In 2009, the first single-cell RNA-seq experiment was published, profiling the transcriptomes of just a handful of mouse blastomeres, each cell sequenced by hand, one at a time. Fast forward to today, we’re building giga-scale single-cell perturbation atlases, training foundation models on datasets of over 100 million cells, and developing virtual cell models as “co-pilots” to simulate complex biological systems in silico.
It’s easy to get swept up in the scale and ambition of today’s single-cell efforts. But none of it would be possible without the steady innovation from kit providers and technology developers. They’ve pushed the limits on how many cells we can measure and how deeply we can profile each one. Kit providers may not sound glamorous, but they are modern-day van Leeuwenhoeks and Hookes. Like the inventors of the microscope, they gave us our first clear view into the cell’s inner workings.
Over the past decade, 17 companies and 61 (!) kits have emerged to interrogate the transcriptional states of a single cell.
To help readers navigate the landscape, we are releasing a live database of all existing single-cell kits and technologies at https://latch.bio/spatial-single-cell-landscape?type=single-cell
This is an extension of our previously published spatial technologies market map, which featured 20 companies and 42 products defining spatial biology today.

What’s Covered
In this article, we walk through the landscape of existing commercial single-cell technologies.
We will cover:
-
Key Technologies
How do you isolate or identify a single cell? -
Key Chemistries
How do you read the mRNA from the single cell? -
Methods by Attributes: Comparisons following criteria:
-
Number of Cells Supported
High-, mid-, and low-throughput technologies -
Analyte Support
Whether the platform supports RNAs only or includes DNA, proteins, or epigenetic markers. -
Multiomics Support
Support for capturing multiple analytes from the same cell. -
FFPE Compatibility
Whether the technology can be applied to formalin-fixed paraffin-embedded samples. -
Cloud Bioinformatics
Whether vendor-provided software is included to analyze and visualize results.
-
Part 1: How do you isolate a single cell? Key approaches
Single-cell isolation is the first step in most single-cell sequencing workflows. There are four primary technology groups used to achieve this, each with distinct mechanisms and trade-offs:
-
Capsule-based Methods
These approaches use microfluidic droplets or capsules as miniature reaction chambers to isolate individual cells. Each capsule contains the necessary reagents for downstream processing, such as barcoding and lysis.-
Key Platforms:
-
10X Genomics Chromium
-
Atrandi Biosciences Semi-Permeable Capsules
-
Bio-Rad ddSEQ
-
-
-
Microwell-based Methods
Microwell systems rely on physical wells small enough to capture a single cell. Some platforms include integrated imaging systems to confirm the presence of a single cell in each well before proceeding to library prep.-
Key Platforms:
-
Takara Bio ICELL8
-
Singleron GEXSCOPE® chip
-
BD Rhapsody
-
-
-
Combinatorial Indexing Methods
Instead of physically isolating single cells, these methods rely on repeated rounds of molecular barcoding across split-pool steps. Cells or nuclei are indexed through successive rounds of barcode addition, enabling single-cell resolution without compartmentalization.-
Key Platforms:
-
Parse Biosciences Evercode
-
Scale Biosciences Quantum Barcoding technology
-
-
-
Kinetic Confinement Method (pioneered by CS Genetics): Paramagnetic beads carrying barcodes bind to individual cells, and upon heat activation in a viscous buffer, cell lysis and barcode capture occur in a confined microenvironment, enabling high-fidelity single-cell indexing.
-
Matrigel-based Method: A less common approach involves embedding cells in a hydrogel-like matrix (e.g., Matrigel), then performing reactions in situ. This method saw limited adoption and is no longer active commercially.
-
Key Platform:
-
Scipio Bioscience Asteria™ (Company ceased operations in September 2024; included here for completeness)
-
-
We walk through each method and the commercial kits that implement them in the sections below.
Capsule-based Methods
In capsule-based approaches, each single cell is enclosed in a physically isolated compartment that enables independent biochemical processing. Within this capsule, cell lysis releases RNA, which undergoes reverse transcription and cDNA synthesis using reagents that include unique molecular identifiers (UMIs) and cell barcodes. The compartment ensures that the barcoded cDNA generated corresponds to a single cell.
10x Genomics
Instrument required: Yes
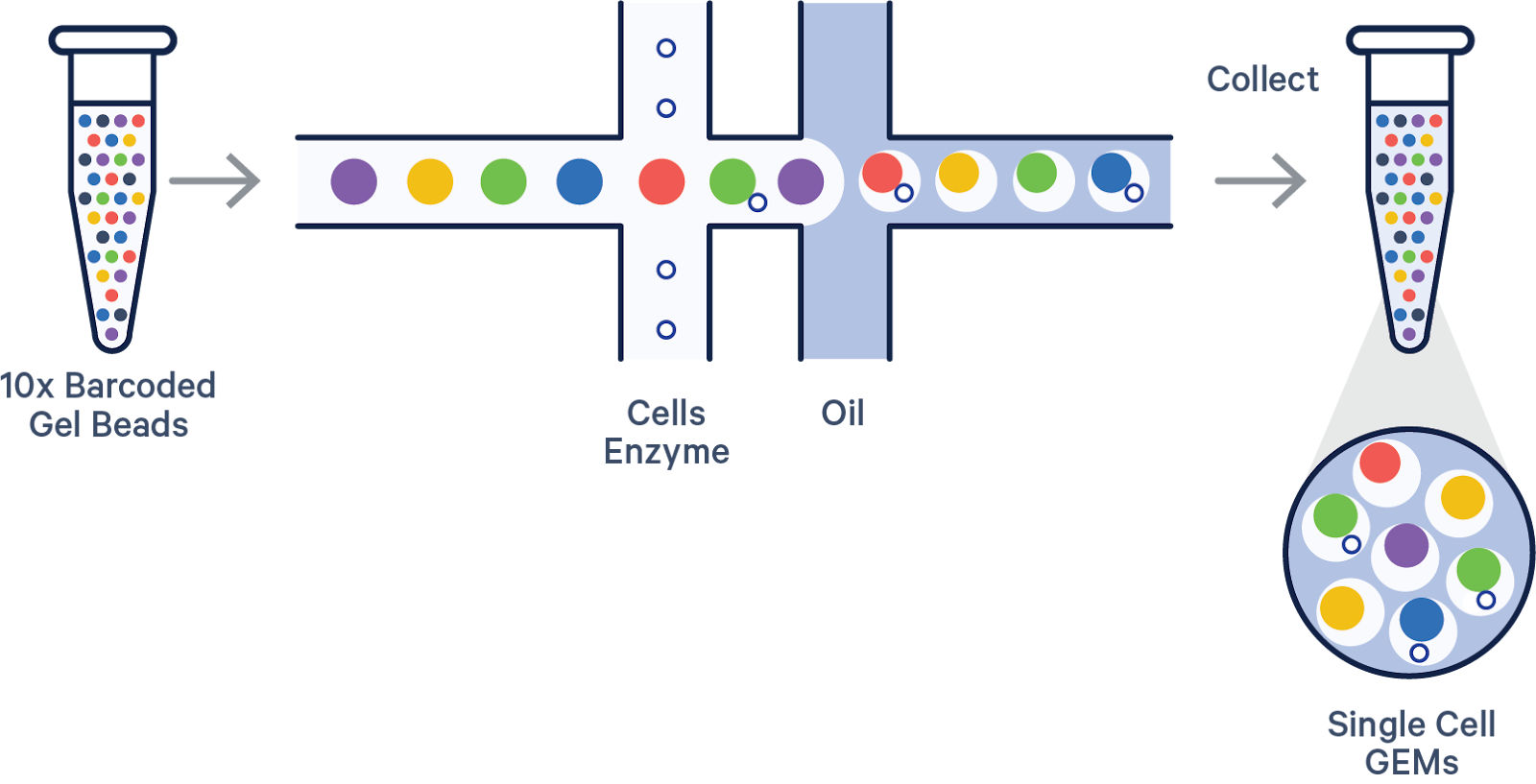
10x Genomics uses microfluidic droplet generation to co-encapsulate single cells and barcoded gel beads within oil emulsions. Each gel bead is functionalized with oligonucleotides containing a cell-specific barcode and a poly-dT sequence that captures mRNA. Once inside the droplet, the cell is lysed, and mRNA is hybridized to the bead’s oligos. Reverse transcription occurs within the droplet, producing barcoded cDNA tagged with both UMI and cell barcode.
Atrandi Biosciences
Instrument required: Yes
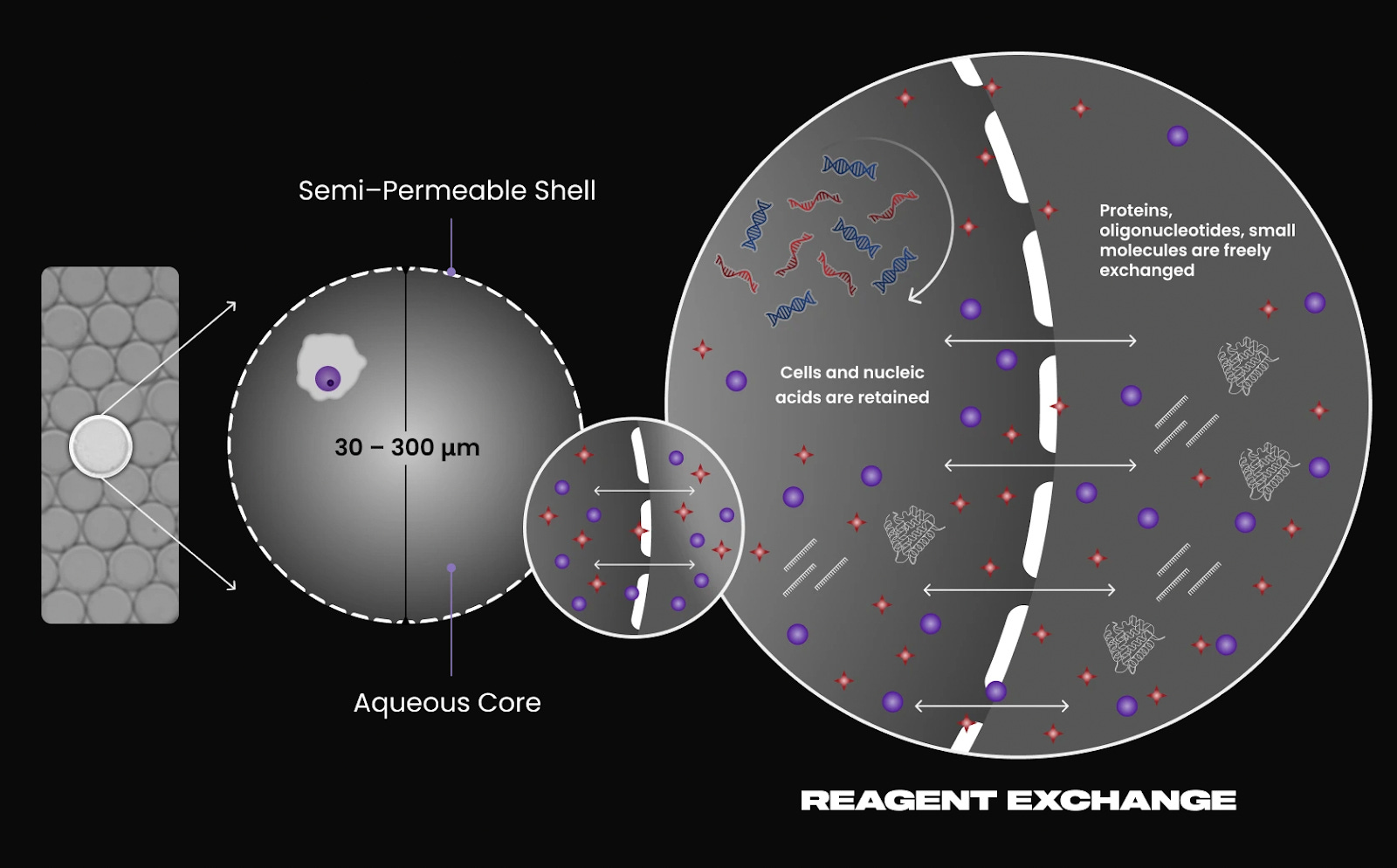
Atrandi introduces semi-permeable capsules (SPCs) formed from hydrogel polymers. Each SPC encapsulates a single cell and is engineered to allow diffusion of small molecules such as enzymes and nucleotides, while retaining larger macromolecules like RNA and DNA. Cells undergo lysis inside the capsule, followed by in-capsule reverse transcription and amplification. The porous structure allows reactions to be performed in bulk solution without cross-contamination, making the workflow highly scalable.
Bio-Rad ddSEQ
Instrument required: Yes
The Bio-Rad ddSEQ system combines microfluidics with droplet partitioning. Cells are individually encapsulated into nanoliter droplets containing barcoded primers immobilized on beads. Each droplet functions as a miniature reaction chamber, where cell lysis, mRNA capture, and reverse transcription take place. The barcoded beads encode both a unique cell barcode and UMI, allowing for downstream demultiplexing and transcript quantification. The ddSEQ platform is particularly suited for targeted gene panels and integrates with Illumina sequencing workflows.
Mission Bio Tapestri
Instrument required: Yes
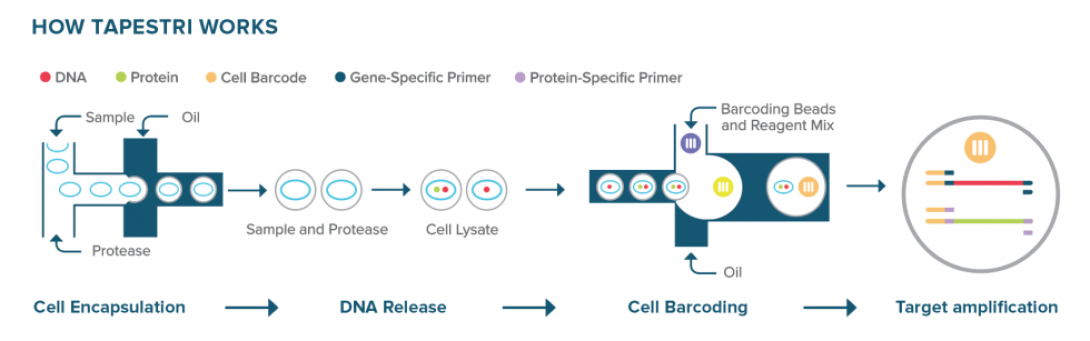
Mission Bio’s Tapestri platform performs targeted single-cell DNA and protein analysis using a two-step microfluidic droplet workflow. In the first step, individual cells are encapsulated into droplets along with lysis buffer and protease, releasing genomic DNA and surface proteins. These lysates are then recovered and re-encapsulated in a second droplet step with barcoded primers targeting specific genomic loci. Within these droplets, PCR-based amplification captures genetic variants alongside cell-identifying barcodes. Surface protein expression is simultaneously measured via antibody-oligo conjugates included in the workflow.
This two-step separation of cell lysis and barcoding allows for optimized conditions at each stage and ensures high specificity in variant detection. The Tapestri platform enables simultaneous profiling of single-nucleotide variants (SNVs), insertions and deletions (INDELs), copy number variations (CNVs), and protein expression from the same single cell, providing multi-omic resolution ideal for applications in cancer genomics and cell therapy development.
Illumina (previously Fluent PIP-seq Kit)
Instrument required: No
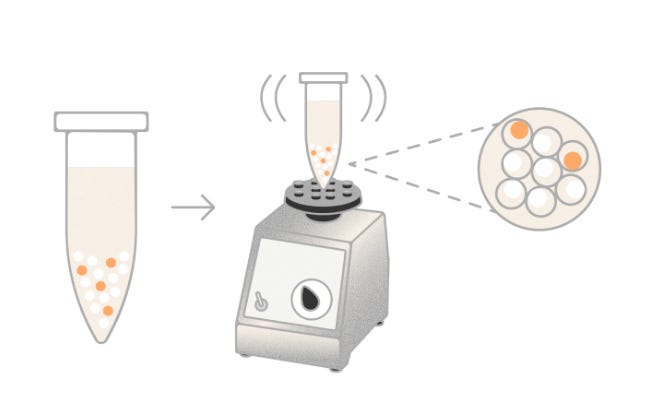
Illumina’s PIPseq™ Single-Cell RNA Prep, originally developed by Fluent BioSciences, employs a microfluidics-free, vortex-based method to partition individual cells into hydrogel-based capsules known as Particle-templated Instant Partitions (PIPs). By simply vortexing a mixture of cells, barcoded beads, and reagents, the system forms emulsions that encapsulate single cells without the need for specialized instruments. Within each PIP, cell lysis, mRNA capture, and reverse transcription occur, utilizing barcoded oligonucleotides to tag transcripts uniquely per cell
Microwell-based Methods
Singleron: SCOPE® Technology
Instrument required: No
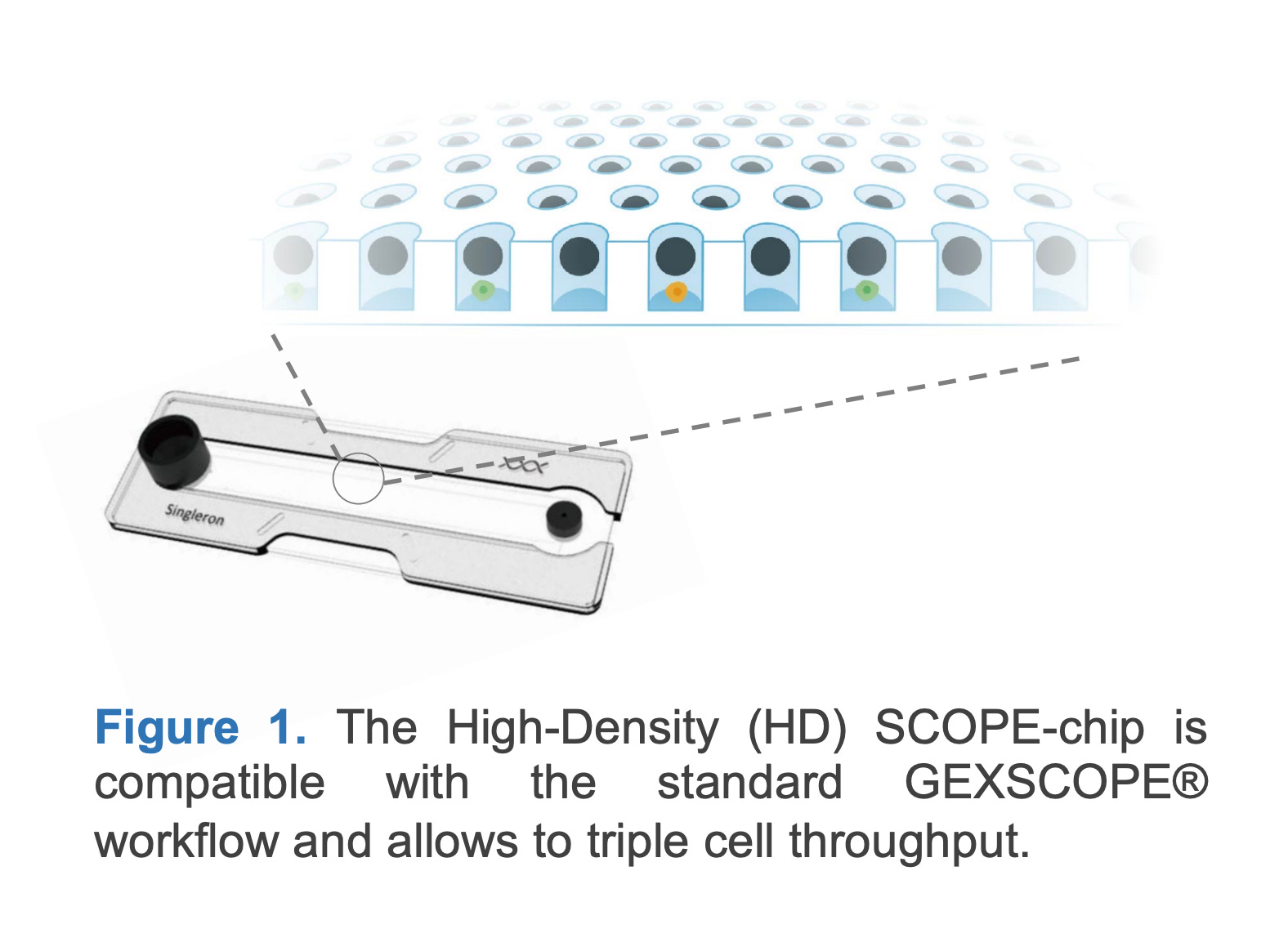
The SCOPE® platform uses a custom-designed PDMS chip containing thousands of uniformly sized microwells etched into the surface. Cells are introduced by gravity and settle into the wells, which are preloaded with barcoded oligonucleotides. The chip is then sealed with a reagent-containing cover to initiate cell lysis and reverse transcription. The chip layout ensures minimal cross-talk between wells and allows for efficient reagent diffusion. Its geometry supports high capture efficiency and is optimized for “one-pot” reactions, reducing sample handling and transfer loss.
TakaraBio
Instrument required: Yes

Takara Bio’s ICELL8® cx is a high-throughput microwell-based platform that captures up to 5,184 single cells or nuclei on a nanowell chip. Unlike droplet- or flow-based systems, it uses high-resolution fluorescence imaging to identify and select viable, singlet cells before molecular processing, ensuring precise cell inclusion. Each selected well receives reagents for full-length transcriptome amplification using SMART-Seq chemistry. The chip supports parallel processing of up to eight samples and is compatible with multi-omic workflows, including RNA-seq, TCR profiling, and ATAC-seq. Its imaging-guided selection and open protocol design make it well-suited for rare or fragile cell types.
BD Biosciences: Rhapsody™
Instrument required: Yes
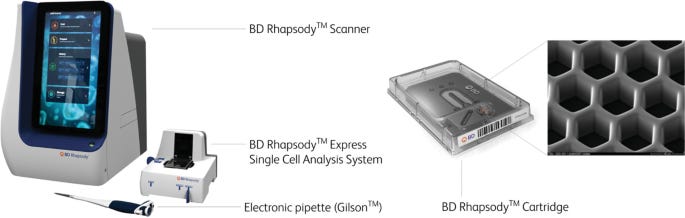
The BD Rhapsody™ system is based on a microwell cartridge that contains tens of thousands of tightly packed wells arranged in a high-density grid. Each well is engineered to capture a single cell and a single barcoded magnetic bead, enabling localized reactions for mRNA capture. The beads are functionalized with oligonucleotides containing cell barcodes, unique molecular identifiers (UMIs), and poly-dT sequences for hybridizing to polyadenylated RNA.
Once cells are loaded by gravity and settle into the microwells, lysis buffer is introduced directly onto the cartridge. The released mRNA hybridizes to the barcoded oligos on the beads. After hybridization, beads are magnetically recovered and pooled for reverse transcription and library preparation.
BD offers two versions of the Rhapsody system to accommodate different throughput needs:
-
BD Rhapsody Express:
A benchtop instrument that processes a single microwell cartridge per run. This format is ideal for moderate-throughput labs and supports flexible experimental design with integrated fluidics and imaging for quality control. -
BD Rhapsody HT Xpress:
A high-throughput variant that can process up to 8 cartridges in parallel. This system is designed for large-scale studies, offering substantial gains in cell throughput, reagent batching, and hands-off operation. The HT configuration enables processing of up to 160,000 cells per run (assuming 20,000 cells per cartridge), making it suitable for cohort-scale immune profiling or large multiplexed experiments.
Flexomics: FLEX™ Chip
Instrument required: No
The FLEX™ chip is a microscope-compatible picowell array designed to capture and isolate individual cells in a spatially resolved format. Each picowell physically traps a single cell, allowing researchers to perform cell-based assays directly on-chip. The chip also supports live-cell imaging, functional perturbations, and phenotypic assays without the need for sample transfer.
After cellular assays are completed, the same chip is used for molecular analysis such as transcriptomics or proteomics. Molecular barcoding reagents are added to capture both mRNA and oligo-tagged antibodies within each well. Cell-of-origin information is preserved from phenotypic imaging through to sequencing because each cell remains in a fixed spatial location throughout the workflow.
Celldom: CloneXplorer Platform
Instrument required: Yes

CloneXplorer is Celldom’s next-generation live single-cell assay platform that combines continuous functional imaging, molecular profiling, and automated cell retrieval in a single, high-throughput system. Built on a microfluidics-free design, CloneXplorer uses a standard 96-well plate format, where each well contains thousands to tens of thousands of microwells, allowing simultaneous analysis of over 100,000 single cells in one experiment.
The platform enables extended, real-time observation of single-cell dynamics through timelapse 4-color imaging, capturing morphological, functional, and molecular behaviors at high resolution. This capability is particularly powerful for applications such as CAR T-cell potency testing, monoclonal antibody (mAb) or TCR discovery, clonal selection for cell line development, and precision oncology. AI-powered cell detection and tracking algorithms analyze each cell’s behavior and link functional outputs to downstream sequencing-based molecular profiles. CloneXplorer also includes an on-instrument picker, which allows researchers to isolate specific cells or clones of interest for further expansion or analysis.
BioSkryb
Different from BD and Singleron, BioSkryb platforms use standard 96- and 384-well plates, modified for single-cell compatibility. The well design allows for direct sorting of single cells via FACS or automated liquid dispensers. Each well serves as a discrete reaction chamber for PTA-based whole genome amplification or RNA processing.
Combinatorial-Indexing Methods
Combinatorial indexing enables single-cell resolution without physically isolating each cell. Instead, cells or nuclei are processed in bulk, and unique barcodes are introduced through multiple rounds of molecular tagging. Each round involves pooling, splitting, and re-barcoding the sample, generating statistically unique barcode combinations corresponding to individual cells. This approach eliminates the need for microfluidics or specialized chips and scales efficiently to hundreds of thousands to millions of cells per run.
Scale Biosciences: Quantum Scale Technology
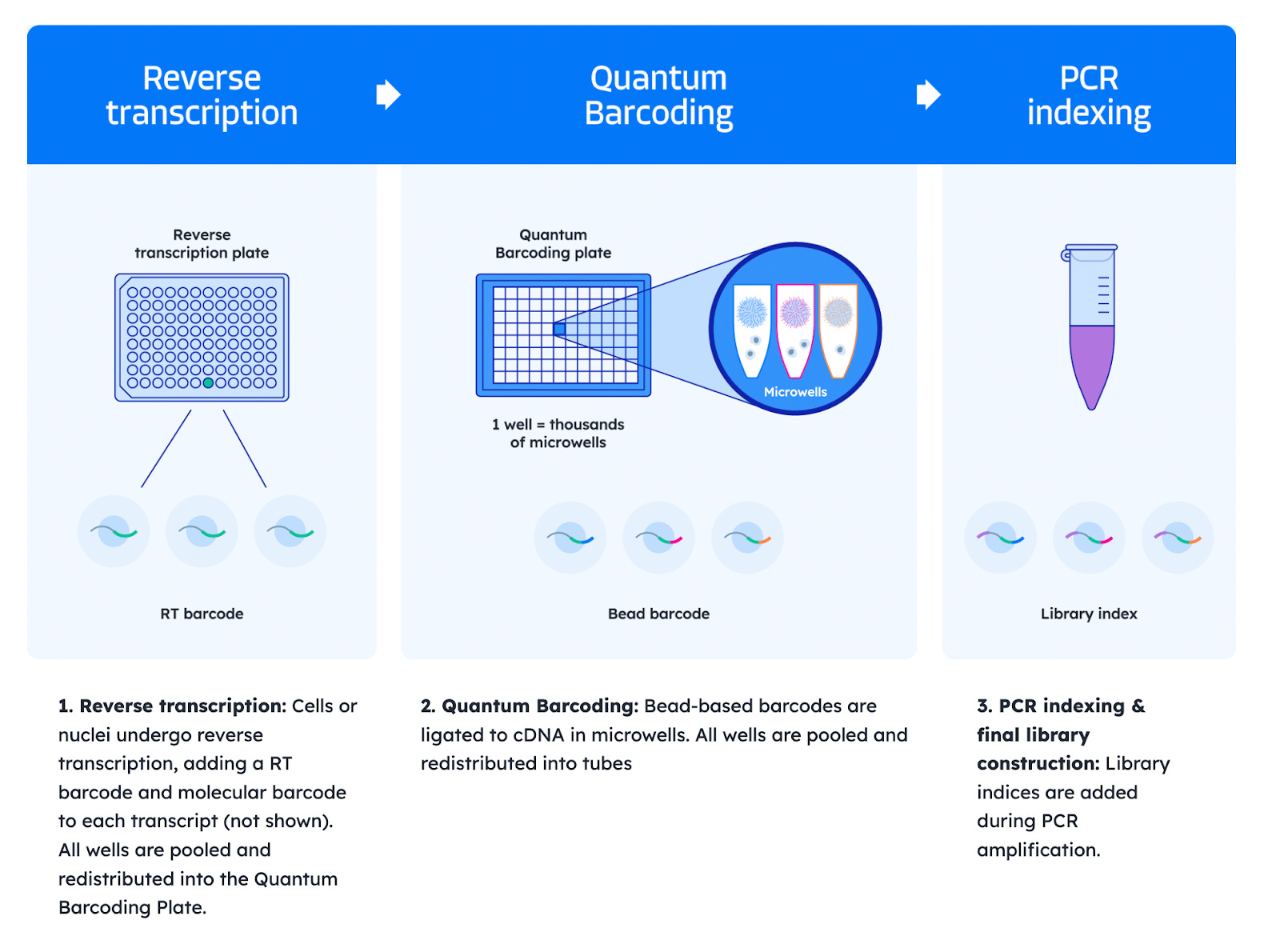
Scale Biosciences’ Quantum Barcoding™ platform employs a three-round barcoding strategy optimized for speed and simplicity:
-
Reverse transcription: In the first round, cells or nuclei undergo reverse transcription, adding an RT barcode and a molecular barcode to each transcript (Result: cDNA of Transcript X + RT barcode + Molecular barcode). All cells are pooled and redistributed to the second plate, the Quantum Barcoding Plate.
-
Quantum Barcoding: In the second round, barcoded cDNA is ligated to beads within a Quantum Barcoding Plate, each well of which contains a unique barcode (Result: Microwell barcode + previous cDNA of Transcript X + RT barcode + Molecular barcode). All wells are then pooled and redistributed into tubes.
-
PCR indexing and final library construction: Library indices are added during PCR amplification.
This plate-based ligation replaces the need for multiple split-pool steps and significantly reduces hands-on time. The resulting barcode combinations uniquely tag transcripts from each single cell. This method supports up to 675 million unique barcode combinations, making it well suited for profiling millions of cells in a single run. The streamlined, low-touch protocol is also compatible with automated liquid handling.
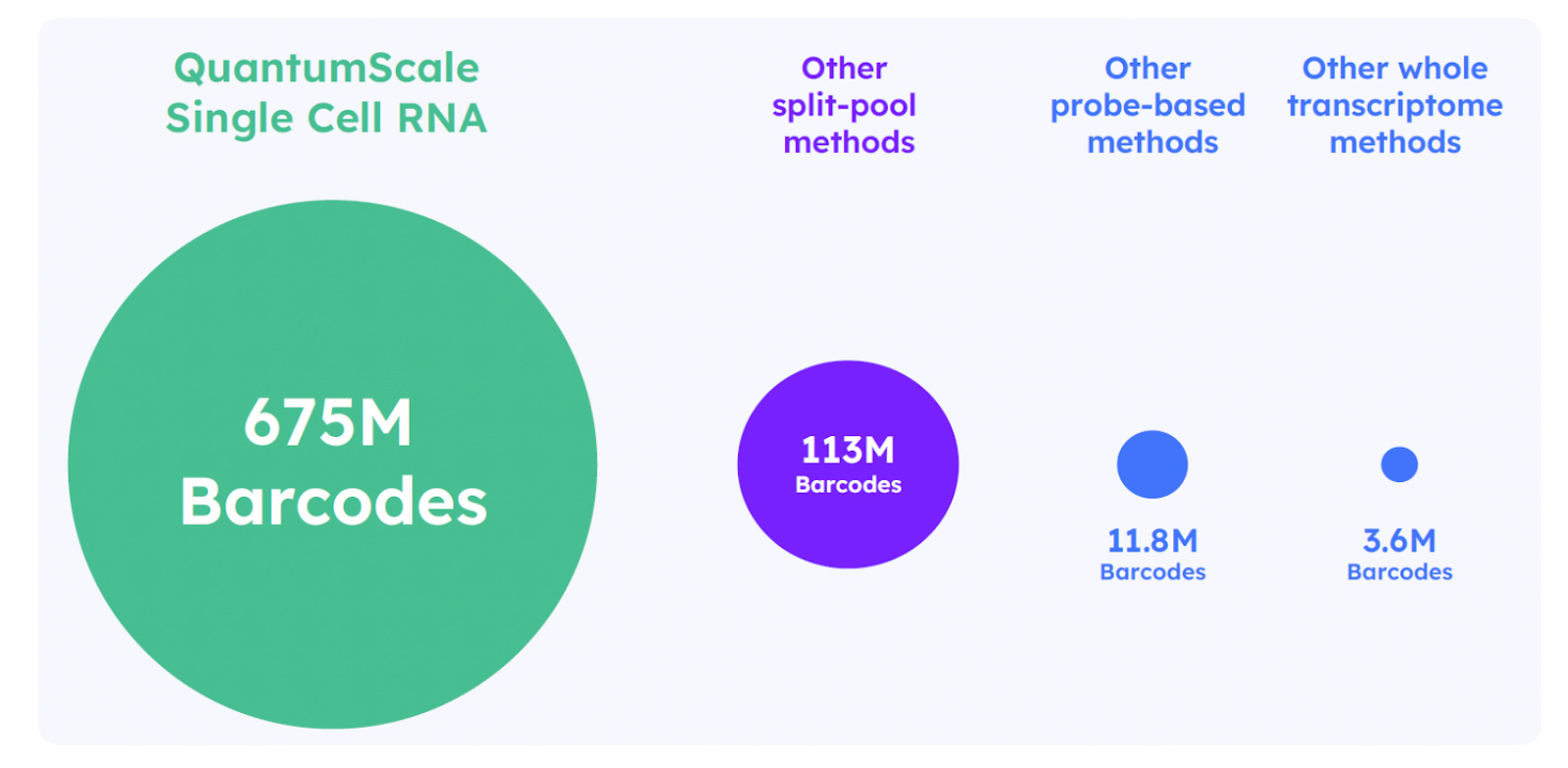
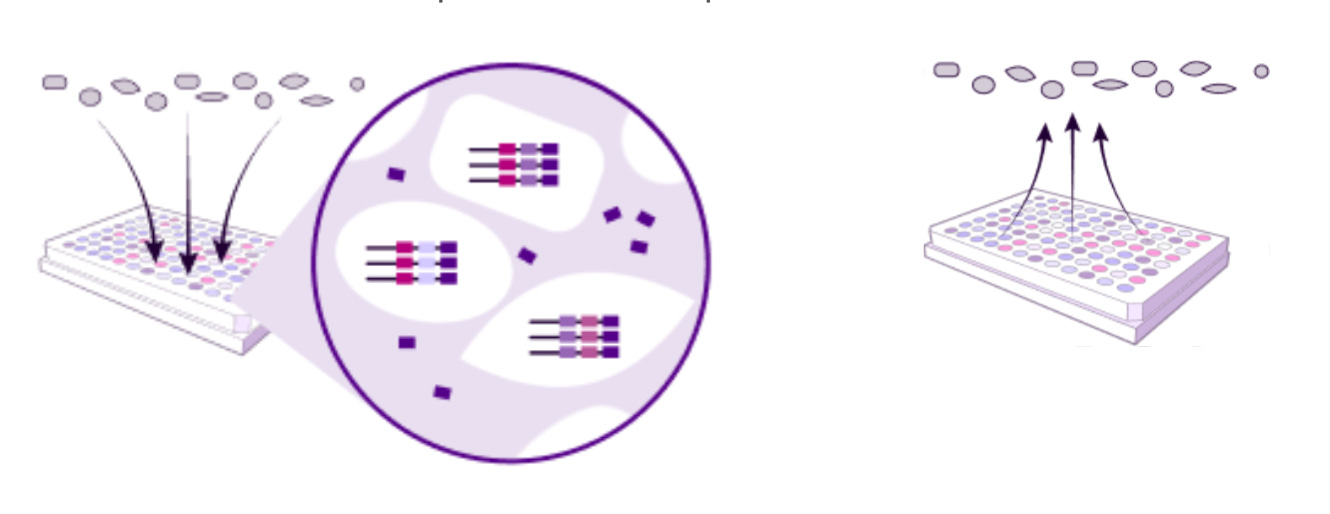
Parse Biosciences: Evercode Technology
Parse’s Evercode™ platform uses a four-round combinatorial barcoding strategy to uniquely label RNA transcripts from individual cells or nuclei.
-
Reverse transcription:
-
Split: Samples are distributed into wells and the first, sample-specific barcodes are applied to fixed cells or nuclei with an in-cell reverse transcription (RT) reaction.
-
Pool: Cells from each well are pooled together.
-
Result of first step: Cell + Sample-specific barcode
-
-
Ligation:
-
Split: Cells or nuclei are distributed across a plate and an in-cell ligation appends the second barcode.
-
Pool: Cells from each well are pooled together.
-
Result of 2nd step: Cell + Sample-specific barcode from 1st step + Second barcode from in-cell ligation
-
-
Ligation
-
Split: The third barcode is applied with another in-cell ligation after the cells or nuclei are split across a plate.
-
Pool: Cells from each well are pooled together.
-
Result of 3nd step: Cell + Sample-specific barcode from 1st step + 2nd barcode from in-cell ligation + 3rd barcode from in-cell ligation
-
-
Lysis + PCR:
-
The pooled cells are divided across several sublibraries. The cells are lysed and the fourth, sublibrary-specific barcode is applied by PCR.
-
Result of 4th step: Cell + Sample-specific barcode from 1st step + 2nd barcode from in-cell ligation + 3rd barcode from in-cell ligation + 4th barcode applied by PCR.
-
-
Library Prep: The library preparation appends adapters ready for loading on any next-generation sequencer.
One of the unique features of Parse Biosciences kit is cells can be fixed and stored up to 6 months, supporting flexible batching and processing across days. The system enables profiling of up to 5 million cells and 384 samples per experiment without requiring specialized instrumentation.
Kinetic Confinement Method
CS Genetics: SimpleCell™ platform
CS Genetics creates its own category, offering a unique method known as called Kinetic Confinement (KC).
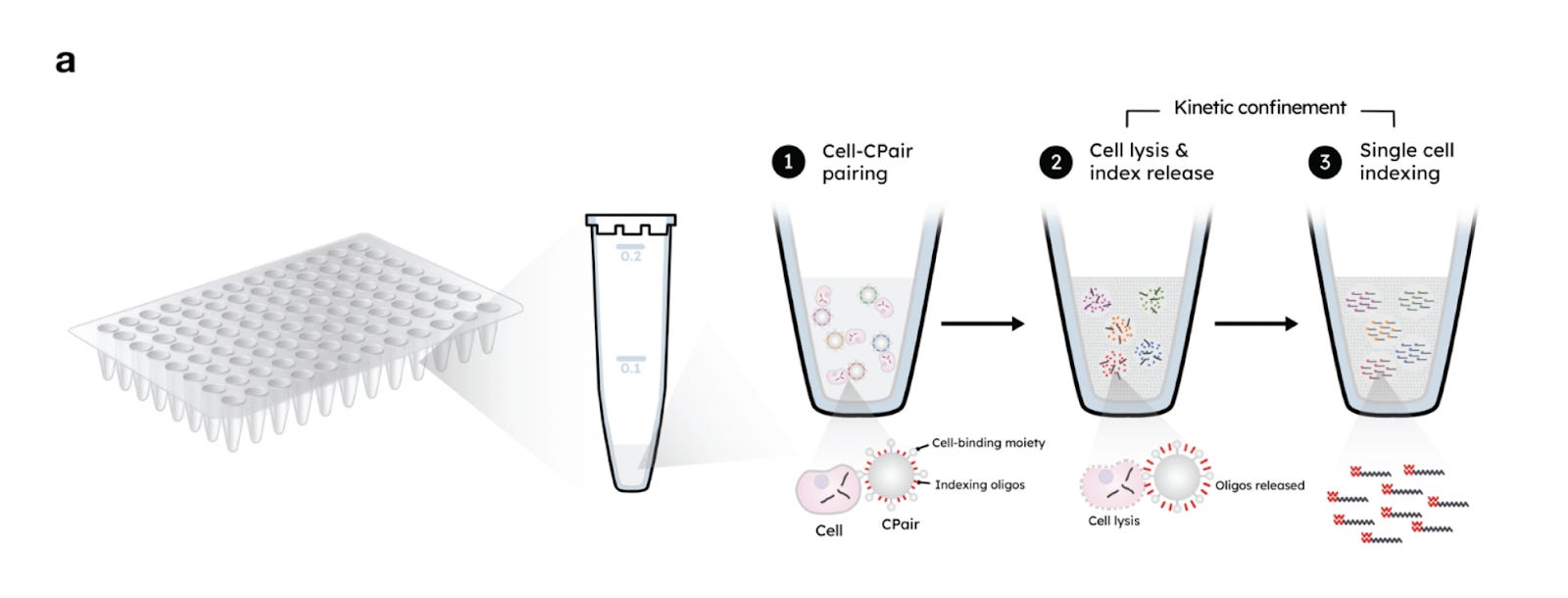
KC operates using two key components:
-
CPair Beads: These are paramagnetic beads roughly the size of mammalian cells. Each bead is coated with unique indexing oligonucleotides (comprising a poly-dT sequence and a cell-specific barcode) and antibodies that enable general cell binding.
-
Kinetic Confinement Buffer (KCB): This is a thick, viscous solution that limits molecular diffusion and includes a heat-activated lysis agent. It also acts as a cryoprotectant, allowing samples to be stored and processed later.
In practice, cells are combined with the CPair beads, then KCB is added. Heating the mixture triggers both cell lysis and the release of oligonucleotides from the beads. This creates a concentrated microenvironment around each bead where mRNA molecules and barcodes are in close proximity, enabling efficient hybridization.
For reverse transcription, second-strand synthesis is initiated using randomly distributed primers instead of traditional 5’-anchoring methods. This design eliminates the need for unique molecular identifiers (UMIs). Instead, each transcript is marked by the random position at which second-strand synthesis begins, termed the “5S” site. Since it’s statistically improbable for two independent transcripts to start at the same site, duplicates can be confidently identified as PCR artifacts, leading to cleaner, more accurate data.
Part 2: How do you read mRNA? Key Chemistries:
Refresher on the Direction of RNA
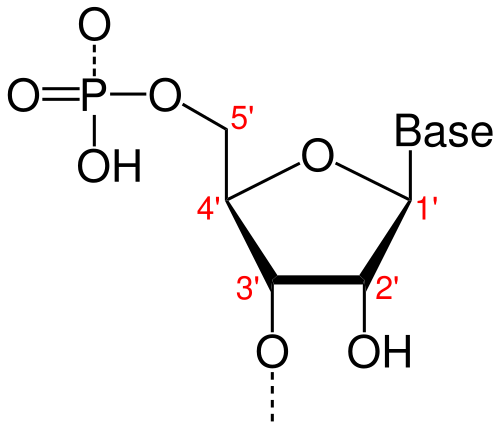
In both RNA and DNA, each strand has a built-in direction, determined by the structure of its sugar-phosphate backbone. This directionality is defined by the numbering of carbon atoms in the ribose (or deoxyribose) sugar:
-
The 5′ end refers to the fifth carbon, where a phosphate group is typically attached.
-
The 3′ end refers to the third carbon, which carries a free hydroxyl (-OH) group.
This 5′ to 3′ orientation is critical for how genetic material is copied, transcribed, and read.
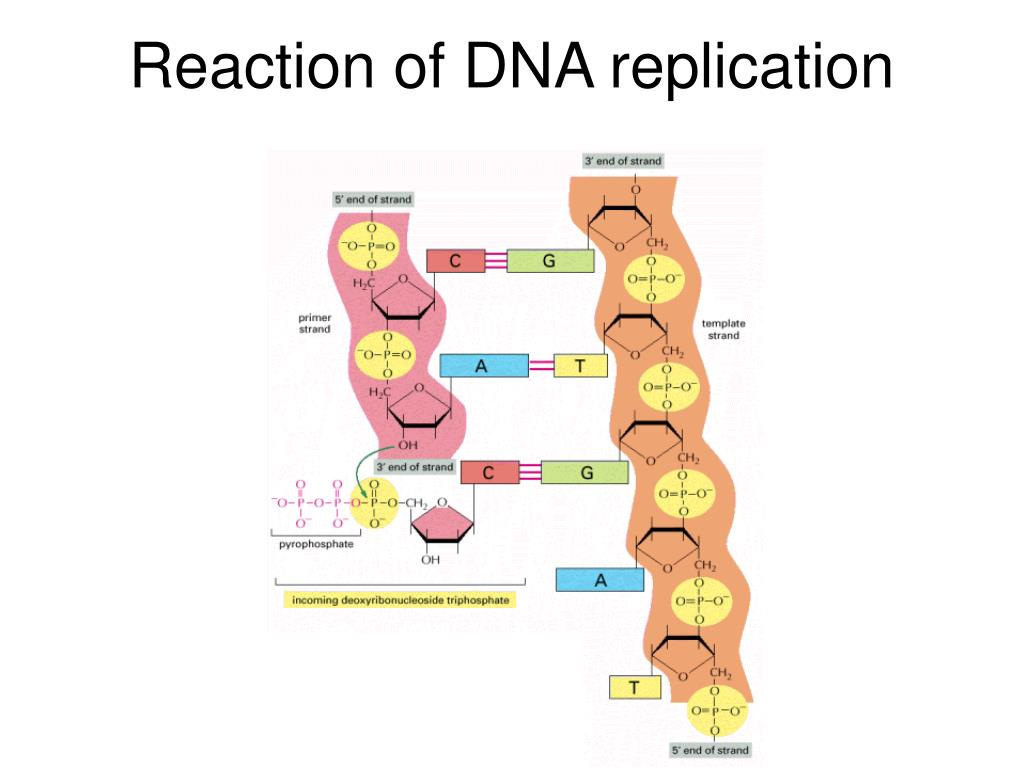
DNA can only be synthesized in vivo in the 5′-to-3′ direction. Here’s why:
Incoming nucleotides arrive as triphosphates (e.g., ATP, GTP), which contain high-energy bonds between their phosphate groups. The hydroxyl group (-OH) at the 3′ end of the existing strand acts as a nucleophile, an electron-loving group that seeks out positively charged or electron-deficient atoms. It performs a nucleophilic attack on the α-phosphate of the incoming nucleotide, which is electron-rich due to the surrounding negatively charged oxygen atoms, but structurally set up to be reactive due to the strain in the triphosphate bond.
This reaction breaks off two phosphate groups (as pyrophosphate) and forms a phosphodiester bond, extending the DNA strand by one nucleotide.
This chemical mechanism is unidirectional. There’s no equivalent reactive group on the 5′ end, so all DNA and RNA synthesis proceeds exclusively in the 5′ → 3′ direction.
Why does directionality matter for RNA sequencing?
The 5′ to 3′ structure of RNA directly shapes how we design sequencing methods. Because all polymerases extend RNA or DNA by adding nucleotides to the 3′ end, reverse transcription (converting RNA into cDNA) naturally begins at the 3′ end of the RNA molecule.
Modern single-cell RNA-seq protocols take advantage of this property by anchoring capture primers at the polyadenylated (polyA) tail, a common feature of mature mRNA, allowing selective and efficient initiation of cDNA synthesis. This foundational principle is what underlies 3′ chemistry, one of the most widely used approaches in single-cell transcriptomics.
3’ Chemistry
3′ chemistry in single-cell RNA sequencing refers to protocols that capture and sequence only the 3′ end of polyadenylated RNA transcripts.

3′ chemistry relies on oligo-dT primers to hybridize to the poly-A tail of mRNA molecules. These primers are often part of a larger molecule (such as the GEM-X 10X 3’ Kit’s Gel Bead above) that also includes:
-
A cell-specific barcode (to identify which cell the RNA came from)
-
A UMI (to deduplicate PCR artifacts and count original transcript molecules)
-
A PCR handle or sequencing adapter
The structure allows all mRNA transcripts from a single cell to be reverse-transcribed and tagged with the same barcode and different UMIs.
In 3′ single-cell RNA-seq chemistry, individual cells are isolated (e.g., in droplets or wells) and lysed to release mRNA, which is captured via oligo-dT primers that hybridize to the poly-A tails. These primers are pre-attached to a scaffold containing a cell barcode and a unique molecular identifier (UMI), enabling transcript origin and quantification. Reverse transcription is then performed, generating cDNA fragments anchored at the 3′ end of transcripts. All cDNA is pooled and PCR-amplified using universal adapters, and libraries are sequenced such that Read 1 captures the barcode and UMI, while Read 2 sequences a short region adjacent to the 3′ end of the transcript.
This 3′ capture approach has several benefits. First, by targeting the poly-A tail present on nearly all mature mRNAs, it enables broad transcriptome coverage without needing gene-specific primers or probes. This means any polyadenylated RNA can, in principle, be captured, offering wider, unbiased capture of the transcriptome. Second, because only the region near the 3′ end is reverse-transcribed and sequenced, the resulting libraries are small, and short reads (~100 bp) are sufficient to map the transcript to a gene. This significantly reduces sequencing costs per cell, enabling higher throughput, often profiling tens of thousands of cells to hundreds of thousands in a single experiment.
Examples of 3’ Kits:
-
10x Genomics: Chromium Single Cell 3′ v3.1
-
Parse Biosciences: Evercode Whole Transcriptome
-
BD Biosciences: Rhapsody WTA
-
Singleron: GEXSCOPE® scRNA-seq
-
Flexomics: FLEX™ RNA + Protein
However, this method cannot reliably resolve transcript isoforms, splicing events, or full-length gene structures. These features typically involve differences in internal or 5′ exons, alternative splice sites, or variable transcription start sites, all of which are located far upstream of the 3′ end.

Full-length or 5′ capture strategies are better suited for applications requiring this level of resolution.
5’ Chemistry
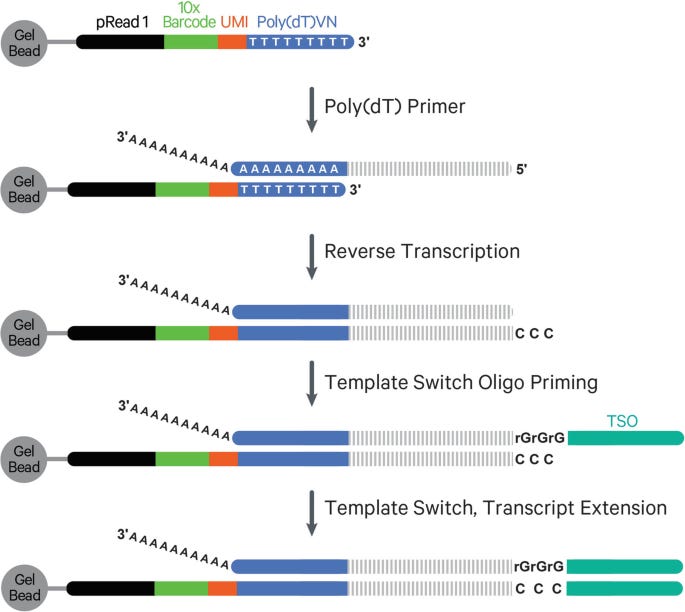
5′ chemistry in single-cell RNA sequencing refers to protocols that capture and sequence the 5′ end of polyadenylated RNA transcripts. This strategy is particularly valuable for studying transcription start sites and for recovering full-length immune receptor transcripts (e.g., TCR and BCR) necessary for V(D)J repertoire profiling.
Reverse transcription in 5′ chemistry still initiates at the 3′ poly-A tail, using an oligo-dT primer that also includes a cell barcode, UMI, and a partial sequencing adapter. As reverse transcriptase synthesizes cDNA toward the 5′ end of the mRNA, it eventually reaches the 5′ cap structure, a modified guanine nucleotide linked via a 5′–5′ triphosphate bridge. This cap is recognized by the reverse transcriptase’s terminal transferase activity, which adds several untemplated cytosine residues (typically CCC) to the 3′ end of the newly synthesized cDNA.
A template-switching oligonucleotide (TSO), designed with a 3′ GGG motif, hybridizes to these added cytosines and acts as a new template. The reverse transcriptase then extends the cDNA using the TSO sequence, effectively appending a universal adapter to the 5′ end of the cDNA. This completes a fully functional cDNA molecule flanked by known adapter sequences at both ends.
This structure is critical for downstream PCR and sequencing: it ensures that Read 2 starts at the 5′ end of the original mRNA, enabling accurate capture of transcription start sites and full-length variable regions of TCR/BCR transcripts.
Examples of 5’ Kit:
-
10x Genomics: Chromium Single Cell 5′ v2 + Immune Profiling V(D)J Enrichment Kits
-
Singleron: GEXSCOPE® V(D)J and TCR/BCR Kits
In addition to 5’ cDNA synthesis, both kits use targeted enrichment of BCR/TCR regions. This can be done using pools of forward primers that bind to conserved regions at the 5′ end of V gene segments, paired with reverse primers targeting the constant (C) region. This selective amplification enables high-sensitivity recovery of full-length immune receptor transcripts, including the highly diverse CDR3 region, which is essential for reconstructing clonal lineages and profiling immune repertoires at single-cell resolution.
Probe-Based Targeted Gene Panels
Probe-based single-cell RNA-seq chemistries enable highly sensitive and cost-efficient profiling of predefined gene sets. Instead of sequencing the entire transcriptome, these methods selectively enrich for transcripts of interest using hybridization or ligation-based probes. This targeted enrichment allows deeper coverage of low-abundance transcripts while dramatically reducing the required sequencing depth per cell.
In probe-based workflows, enrichment occurs either before or after barcoded cDNA synthesis, depending on the platform. The core mechanisms include:
-
Hybridization-Based Enrichment:
-
Biotinylated or capture-tagged DNA probes are designed to hybridize to complementary sequences on cDNA molecules. Once bound, target-probe complexes are pulled down using beads (e.g. streptavidin-coated magnetic beads), selectively enriching target transcripts.
-
Used by: Parse Biosciences (Gene Select)
-
Ligation-Based Probes:
-
Pairs of oligonucleotide probes hybridize to adjacent sequences on the target transcript. If both probes bind correctly, a ligase joins them to form a single, amplifiable DNA fragment. These ligated products are then barcoded and amplified.
-
Used by: 10x Genomics (Gene Expression Flex Kit)
These strategies are often compatible with cell barcoding and UMIs, preserving single-cell resolution. Some platforms allow simultaneous enrichment of both targeted genes and the whole transcriptome or combine transcript and protein detection.
Example of Probe-Based Kit:
-
10x Genomics: Chromium Fixed RNA Profiling (Flex): Ligation-based probe pairs bind to fixed and permeabilized cells or nuclei. Upon successful hybridization, the pairs are ligated and extended during droplet-based barcoding in GEMs. Oligo-conjugated antibodies can be added before fixation to co-detect surface protein markers. It’s also the only product on the market that enables high-sensitivity targeted profiling from fixed, archived, or low-quality samples (like FFPE).
-
Singleron: FocuSCOPE® Targeted Capture Kit: This kit uses customizable hybridization-based probes to enrich for specific genomic features in parallel with whole transcriptome profiling. It allows up to 10 user-defined regions, including gene fusions, SNVs, and viral RNA, making it a good candidate for oncology, virology, and mutation detection in clinical samples.
-
Parse Biosciences: Gene Select: Uses custom or pre-designed hybridization-based probes are applied after Evercode Whole Transcriptome library prep to selectively enrich genes of interest. Library is hybridized to probes, and bound molecules are captured on magnetic beads. mmune1000 (~1000 genes for immune profiling) or user-defined custom panels is available. .
Full-length RNA Capture Chemistry
SMART-seq
Full-length RNA capture chemistries in single-cell RNA sequencing are designed to preserve and sequence the entire mRNA molecule, from the 5′ cap to the 3′ poly-A tail. Unlike 3′ or 5′ end-tagging methods, which capture only short regions of transcripts, full-length protocols reconstruct complete transcript structures. This enables analyses such as isoform discovery, alternative splicing, allele-specific expression, and transcript-level mutation detection.

The most widely used method for full-length capture is SMART (Switching Mechanism at the 5′ end of RNA Template) chemistry, developed by Clontech and commercialized by Takara Bio. The workflow involves:
-
Poly-dT priming to initiate reverse transcription at the mRNA’s 3′ poly-A tail.
-
As reverse transcriptase reaches the 5′ cap, it adds a short string of untemplated cytosines.
-
A template-switching oligo (TSO) with a 3′ GGG overhang anneals to these Cs, allowing the RT to continue and append a known sequence to the 5′ end of the cDNA.
-
The resulting cDNA, flanked by known sequences, is amplified in full using PCR. No early fragmentation occurs, and no barcode is needed because each cell is processed separately in its own well.
-
Amplified full-length cDNA is typically fragmented (e.g., by tagmentation) and sequenced across the full transcript body, enabling read coverage throughout exons, splice junctions, and UTRs.
Note: In SMART-Seq, reverse transcription and cDNA amplification are performed on physically separated cells (in wells or nanowells), eliminating the need for early barcoding. Each cell is processed independently, and indexing is introduced later during tagmentation or PCR. This contrasts with 10x Genomics’ 5′ chemistry, where the cell barcode and UMI are pre-attached to a gel bead and introduced during reverse transcription. As a result, sequencing is anchored to either the 5′ or 3′ end of the transcript, depending on the kit, and captures only a short fragment adjacent to the barcoded priming site. This design supports high-throughput gene quantification and V(D)J profiling but does not preserve full transcript structure.
Example SMART-seq Kit:
-
Takara Bio: SMART-Seq® v4
Singleron MobiusScope 3’ and 5’ Full-Length mRNA Reading via Circulization
In addition to SMART-based methods, MobiusSCOPE® by Singleron Biotechnologies introduces a new approach to full-length RNA capture through a 3′ and 5′ circularization strategy.
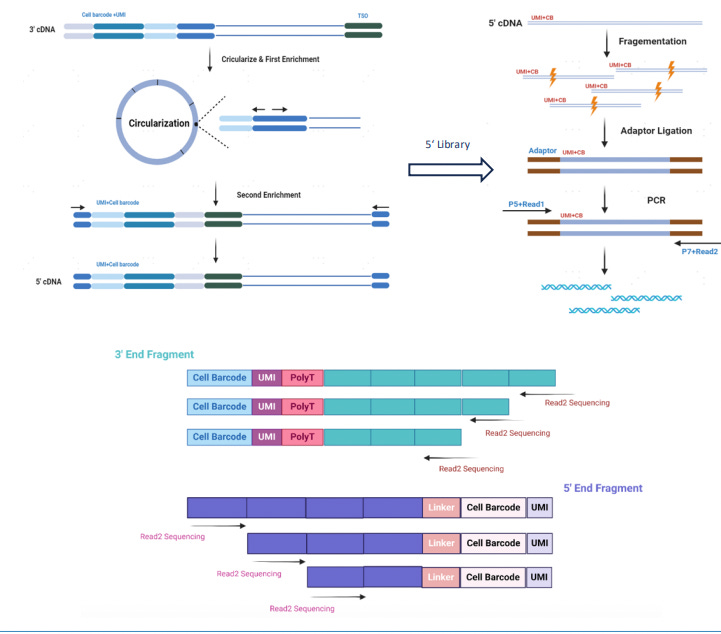
Traditional single-cell RNA-seq methods, such as 3′ or 5′ end-tagging chemistries, attach the cell barcode and unique molecular identifier (UMI) at only one end of the transcript, typically the 3′ poly-A tail. While sufficient for gene expression quantification, this design restricts sequencing to fragments adjacent to the barcoded end and prevents comprehensive recovery of internal transcript features. Once cDNA is randomly fragmented for sequencing, reads originating far from the barcode site cannot be linked back to their original molecule, making full-length transcript reconstruction infeasible.
MobiusSCOPE, developed by Singleron Biotechnologies, overcomes this limitation by using a circularization-based strategy to retain and trace both ends of the transcript. In this workflow, mRNA from each single cell is first captured using poly-T oligonucleotides attached to cell barcoding beads. Reverse transcription is then performed to generate cDNA, during which a unique barcode and UMI are incorporated at the 3′ end of each transcript. This ensures that every cDNA molecule carries a unique molecular tag that identifies its cell of origin and transcript identity.
To capture full-length information, the cDNA is then enzymatically circularized, bringing the 5′ end of the mRNA sequence into close proximity with the barcode and UMI at the 3′ end. A targeted reverse PCR step is used to re-linearize the circularized molecule in such a way that the 5′ sequence remains near the barcode-UMI junction. This re-linearized molecule is then randomly fragmented, and sequencing adapters are ligated to the resulting fragments to prepare the sequencing library.
Because of this molecular architecture, every fragment, regardless of whether it originated from the 5′ end, middle, or 3′ end of the transcript, retains the original barcode and UMI. During analysis, all reads with matching identifiers are grouped and assembled using a proprietary bioinformatics pipeline, enabling accurate reconstruction of full-length transcripts. This method preserves the integrity of transcript isoforms and allows for high-resolution detection of splice variants, fusion transcripts, and full-length immune receptor sequences using standard short-read sequencing platforms.
Part 3: Comparison of Commercial Kits by Attributes
Number of cells
Above 1,000,000 cells per run:
Leaders: Parse Biosciences, Scale Biosciences, 10X Genomics
Parse Biosciences, Scale Biosciences, and 10x Genomics lead the field in high-throughput single-cell RNA sequencing, each offering kits that process over 1 million cells per run.

Parse's Evercode™ Whole Transcriptome and BCR/TCR Mega series reach up to 1 million cells, with the latest Evercode™ WT PENTA V3, launched in February 2025, extending that capacity to an industry-leading 5 million cells per run.

Scale Biosciences follows closely with its QuantumScale Single Cell RNA Extra Large kit, supporting up to 4 million cells.

10x Genomics’ Chromium Single Cell Flex Gene Expression kit, which employs probe-based chemistry for sensitive transcript detection, supports up to 2.56 million cells per run.
While Parse and Scale leverage combinatorial indexing to scale without instrumentation, 10x remains the only droplet-microfluidics platform to achieve this level of throughput.
Hundreds of Thousands Range
Highlights: BD Rhapsody™ HT Xpress System, 10x Genomics, Takara Bio Shasta Total RNA-Seq Kit, Flexomics, Celldom
In the high 100,000s range, 10x Genomics remains a strong player with its Chromium Single Cell Universal 3′ and 5′ Gene Expression kits. The number of cells per run depends on the sample multiplexing strategy. In singleplex mode, one sample is loaded per channel at an input of approximately 20,000 cells. With 8 channels per chip, this yields around 160,000 cells per chip. In contrast, using sample hashing, where samples are tagged with antibody- or lipid-based barcodes and pooled, each channel can accept up to 60,000 cells, resulting in a total of 480,000 cells and up to 96 samples per chip.

The BD Rhapsody™ HT Xpress System, launched in February 2023, uses microwell-based partitioning and achieves a total throughput of up to 800,000 cells per run. Each of the 8 lanes in the cartridge contains hundreds of thousands of microwells designed to isolate single cells. Microwell-based systems have historically had lower throughput due to higher chip fabrication costs and physical space limitations, but the HT Xpress system overcomes many of these issues with improved cartridge architecture and fluidics control.

Another microwell-based platform is Singleron’s GEXSCOPE® HD Chip, which captures 9,000 to 30,000 cells per sample under standard conditions. With CLindex® multiplexing, a technology that allows up to 16 samples to be pooled into a single chip, the system can support up to 160,000 cells per run. However, cell quality may decline beyond 120,000 cells due to elevated doublet rates (around 28%).
Also operating in this range are smaller kit formats from both Parse Biosciences and Scale Biosciences. Parse’s Evercode™ WT and Mega kits, launched in 2021, support up to 100,000 and 1,000,000 cells per run, respectively. Scale’s Quantum Barcoding Modular Kits, introduced in 2025, enable similar mid-range throughput, with options designed for runs of up to 168,000 or 2,000,000 cells depending on configuration.

In October 2024, Takara Bio launched the Shasta Total RNA-Seq Kit, which supports up to 100,000 cells per run while offering full-length transcript coverage. Unlike traditional 3′ or 5′ kits that capture only transcript ends, Shasta uses SMART-seq chemistry to generate full-length cDNA, which is particularly useful for studies focused on isoform-level expression and transcript structure. Takara Bio’s Shasta Total RNA-seq Kit is likely one of the only full-length mRNA technologies in the market at this throughput.


Finally, in the low 100,000s range, companies like Flexomics (founded in 2019) and Celldom (founded in 2016) offer single-cell technologies that integrate microwell-based isolation with high-content imaging and functional assays. These platforms are purpose-built for specialized applications such as compound screening, immunophenotyping, and mechanistic cell biology, making them valuable tools in translational research.
Thousands to Tens of Thousands Range
In the tens of thousands range, we begin to see more specialized products focused on epigenetic profiling and methylation analysis, often with lower cell throughput due to the complexity and sensitivity of these assays.
10x Genomics offers the Chromium Single Cell ATAC-seq and Chromium Single Cell Multiome ATAC + Gene Expression kits, each capable of profiling up to 80,000 cells per run. These kits use droplet-based partitioning to capture chromatin accessibility and, in the case of Chromium Multiome, gene expression from the same cell.
In contrast, Scale Biosciences provides a Single Cell Methylation Kit that supports up to 16,400 cells per run. Unlike 10x ATAC-seq kits, which detect open chromatin regions via transposase-accessible sites, Scale’s methylation kit uses bisulfite-free labeling of methylated cytosines, enabling direct quantification of methylation without harsh chemical treatment. This gentler, indexing-based workflow preserves DNA integrity and is more compatible with sensitive sample types, though at a trade-off in throughput.
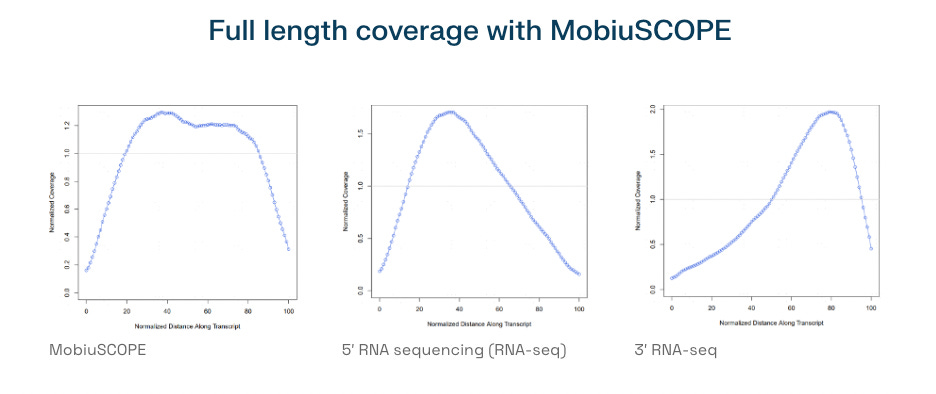
Also within this range is another full-length RNA platform: MobiuSCOPE Full-Length Single Cell RNA Sequencing. Designed to detect complete transcript structures, including 5′ and 3′ ends, MobiuSCOPE supports up to 30,000 cells per run. MobiuSCOPE uses a circularization strategy that enables full-length transcript reconstruction from fragmented reads, an innovative alternative to traditional full-length methods like SMART-seq.
This places Singleron’s MobiuSCOPE it in the same category as Takara’s Shasta platform for isoform-level transcriptomics
Hundreds Range

In the low-throughput category of hundreds of cells per run, BioSkryb Genomics offers its Resolve suite of technologies, including:
-
ResolveOME™: Single-cell multiomics kit for simultaneous RNA and DNA sequencing
-
ResolveDNA® scDNAseq: High-resolution single-cell whole genome amplification and sequencing
-
ResolveDNA® Microbiome: Single-cell genomic profiling for microbial communities
BioSkryb's platform relies on a proprietary primary template-directed amplification (PTA) method that uniformly amplifies the entire genome of a single cell with minimal bias. This method enables extremely high coverage and low error rates, making it well-suited for detecting structural variants, rare mutations, and single-nucleotide variants in individual cells.
While most single-cell transcriptomics platforms compete in the hundreds of thousands or millions of cells per run, BioSkryb occupies a niche space focused on high-fidelity DNA and multiomic profiling for dozens to hundreds of cells. Their technology is particularly valuable for cancer genomics, microbial diversity studies, and developmental lineage tracing.

Note: CS Genetics is an exception here and doesn’t quite fit into our comparison. Their SimpleCell technology does not impose a fixed upper limit on the number of cells per experiment. Because the entire process takes place in free solution, without the need for droplet microfluidics or microwells, the number of cells that can be processed is determined primarily by the number of samples a user runs at a time and whether automated liquid handling robotics is used.
Multiomics Support
Single-cell sequencing has evolved beyond basic transcriptomics into a rich multi-omics landscape. Virtually all vendors now support single-cell whole transcriptome RNA sequencing, which remains the cornerstone for profiling cellular gene expression. Many platforms are extending into multi-modal assays, combining gene expression with other analytes like immune receptor sequences, proteins, genomic DNA variants, chromatin state, and even live-cell functional readouts.
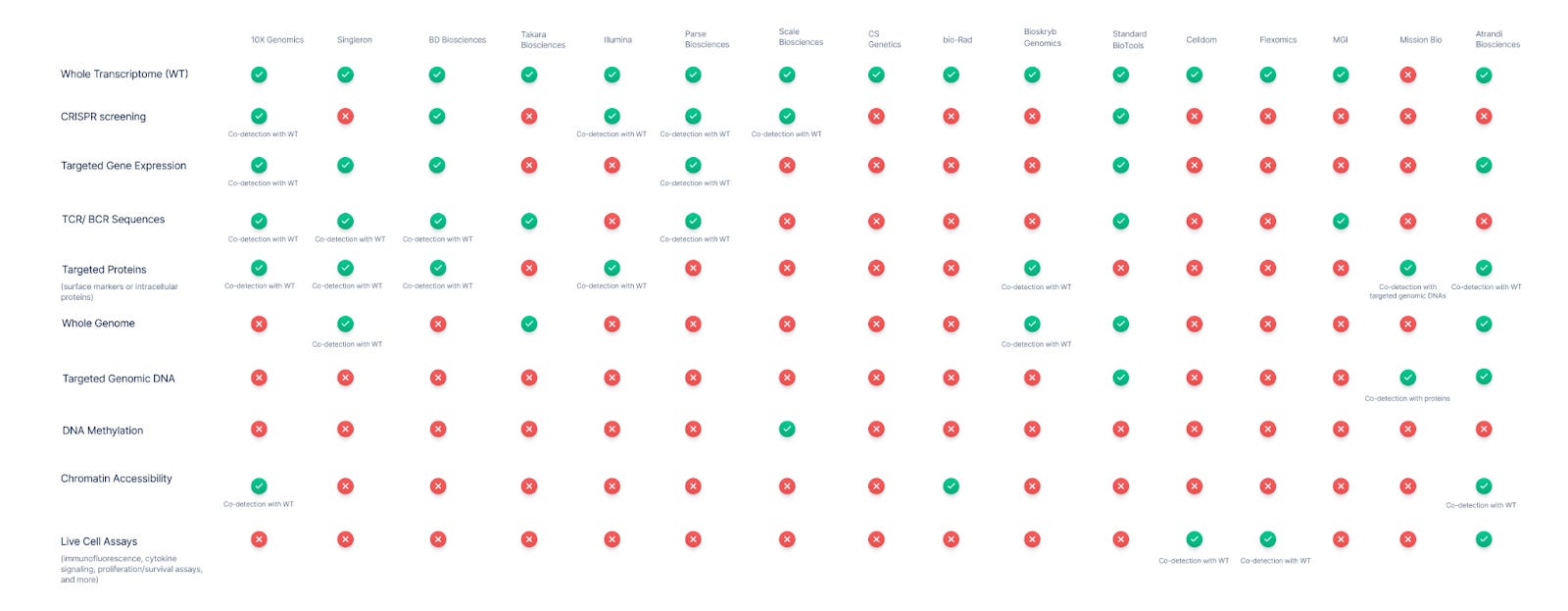
Who are the leaders in multi-modal detection?
-
10X Genomics, Singleron, and BD Biosciences offer the most breadth.
10x Genomics is widely seen as a leader in single-cell multi-omics. Their Chromium platform allows numerous combinations: gene expression (3’ or 5’ RNA-seq) can be paired with CRISPR perturbation readouts (capture of guide RNAs) and with cell-surface protein expression via DNA-barcoded antibodies. 10x also offers a joint assay for chromatin accessibility (ATAC-seq) plus whole transcriptome, enabling epigenomic and transcriptomic profiling in the same cell. Additionally, 10x’s immune profiling kits capture full-length T-cell and B-cell receptor (TCR/BCR) sequences concurrent with mRNA, linking clonal identity to cell state. This breadth makes 10x a benchmark: It supports essentially every analyte in the matrix except DNA methylation and whole-genome DNA sequencing.
Several other vendors have established multi-omic co-detection capabilities as well. BD Biosciences (through the Rhapsody system) enables simultaneous measurement of mRNA, immune receptor repertoire (TCR/BCR), and protein markers in single cells. BD’s system uses a microwell-based capture and has an add-on kit for full-length TCR/BCR profiling that works alongside whole transcriptome or targeted gene expression profiling. Like 10X Genomics, BD also adapted CROP-seq methods to capture CRISPR guide RNAs with mRNA on their platform.

Singleron Biotechnologies has steadily emerged as a major player in integrated single-cell analysis. The company’s platform also supports simultaneous transcriptome profiling with TCR/BCR sequences, surface protein expression, and targeted transcriptome panels, enabling focused gene expression analysis when full-transcriptome depth is unnecessary. A standout feature is its AccuraSCOPE® platform, which supports co-detection of the whole genome and transcriptome from the same cell. This distinguishes it from 10X Genomics and BD Biosciences and positions Singleron as one of the very few vendors to offer such deep genomic-transcriptomic integration.
-
Parse and Scale Biosciences support multi-modal profiling at massive scale (4M+ cells), with Parse offering broader analyte breadth and Scale standing out as the only vendor with single-cell DNA methylation.
Parse Biosciences has emerged with a combinatorial barcoding platform (Evercode) that supports multi-modal readouts at large scale. Parse offers kits for Whole Transcriptome as well as specialized kits for TCR/BCR sequencing (Evercode TCR/BCR, capturing paired receptor chains plus gene expression) They’ve also introduced CRISPR Detect, an add-on allowing single-cell RNA-seq readouts of pooled CRISPR screens by capturing guide RNAs along with transcripts. This puts Parse in the multi-omic arena similar to 10x, albeit using a plate-based barcoding strategy with no custom hardware.
Another new entrant, Scale Biosciences, uses a “Quantum Barcoding” combinatorial index technology. Scale Bio’s platform supports 3’ gene expression, an optional module for CRISPR guide capture (a kit to enrich sgRNAs in parallel with the RNA-seq library), and even a dedicated single-cell DNA methylation sequencing kit–truly the first of its kind on the market. Scale Bio also partnered with BioLegend to enable high-parameter protein detection alongside its RNA-seq: their TotalSeq™ “Phenocyte” solution attaches BioLegend’s DNA-barcoded antibodies to Scale’s workflow to profile dozens of surface proteins per cell concurrently.
-
Mission Bio is the only platform that offers co-detection of targeted genomic DNAs and proteins. Bioskryb provides a robust, new deep “tri-omic” approach (DNA, RNA, and protein profile for every cell).

In terms of genomic DNA and mutation analysis at single-cell level, the clear leader is Mission Bio. While most platforms center on RNA, Mission Bio’s Tapestri platform was uniquely built for targeted DNA sequencing of single cells, with the ability to detect single-nucleotide variants (SNVs), copy number variants (CNVs), and small indels across a panel of genes, for hundreds to thousands of cells. Mission Bio pioneered simultaneous DNA+protein profiling: the platform can amplify target DNA regions of interest and capture protein markers (via antibody-oligo conjugates) from the same cell, linking genotype to immunophenotype.
No transcriptome is measured; this is a DNA-centric multi-omic view, but powerful for applications like cancer, where mutations and surface markers define clones. Mission Bio’s focus on multi-omic genotype + phenotype has influenced others to develop similar “DNA + RNA + protein” approaches.

BioSkryb Genomics has introduced another high-content single-cell multi-omics approach with its ResolveOME kit. This workflow performs unified whole-genome DNA amplification and full-length mRNA cDNA synthesis from the same cell, enabling near-comprehensive sequencing of both the genome and transcriptome of that cell. In practice, a single cell processed with ResolveOME yields a whole-genome sequence (with high coverage uniformity thanks to their PTA technology) together with a full transcriptome (capturing mRNAs end-to-end). BioSkryb further demonstrated adding a third modality: by integrating BioLegend TotalSeq™ antibodies, they can also measure selected surface proteins in those same cells. In other words, BioSkryb’s approach can unite genomic, transcriptomic, and proteomic data from a single cell, a true tri-omic analysis. This is currently a lower-throughput, specialist solution (aimed at deep analysis of tens to hundreds of cells, for example in tumor evolution studies), but it represents a state-of-the-art in multi-omic content per cell.
-
Emerging trend from new entrants (Flexomics and Celldom): Combining live functional cell assays with sequencing.
Finally, new players are combining live-cell assays with sequencing. Celldom and Flexomics both use imaging-based platforms to monitor single-cell behaviors in large arrays of nanowells or picowells, then retrieve those cells for molecular analysis.
Flexomics, for instance, uses a high-density picowell chip with optical barcoding to perform live fluorescence imaging of thousands of single cells (for functional readouts), followed by lysis and capture of mRNA from each well’s cell. This yields paired phenotype and transcriptome data, linking microscopy and sequencing in one workflow. Flexomics emphasizes that any live-cell assay (proliferation, morphological changes, reporter expression, etc.) can be miniaturized on their chip (“Bring Your Own Assay”) and combined with sequencing readouts.
Similarly, Celldom’s platform allows long-term time-lapse imaging of single cells (e.g. to track drug responses or clone formation) in an array of up to millions of nanowells, with an integrated picker to extract individual cells or clones of interest for downstream DNA/RNA sequencing.
These approaches are still emerging, but they offer unique multi-modal data, bridging dynamic cellular function (live-cell phenotypes) with genomic analysis for the first time.
-
Modular multi-omics

Atrandi Biosciences’ Semi-Permeable Capsule (SPC) technology introduces a fundamentally novel paradigm for single-cell multi-omics. Each SPC is a porous hydrogel-based microcapsule that encases individual cells, allowing small molecules and reagents to diffuse in and out while retaining cellular contents. This design enables a sequence of biochemical reactions (lysis, amplification, reverse transcription, bisulfite conversion, and more) to be performed stepwise in the same capsule through simple buffer exchanges. Unlike droplet-based systems that constrain workflows to “one-shot” chemistries, SPCs support modular, multi-step assays under tightly controlled reaction conditions.
While Atrandi Biosciences offers a single-cell DNA microbial and eukaryotic kit, its SPC Innovation Kit allows researchers to mix-and-match and create their own custom, multi-omic single-cell assay.
Example Proof-of-Concepts:
-
Whole-genome sequencing: In a 2023 Genome Biology study (Balan et al.), SPCs enabled high-throughput single-cell genome sequencing of over 60,000 bacteria, achieving strain-resolved assemblies with minimal cross-contamination.
-
Phenotype-genotype linkage: A Nature Microbiology study (Orakov et al.) demonstrated culturing microbial cells within SPCs, monitoring their growth phenotypes, and linking those to genomic identity.
-
Targeted gene expression (RNA cytometry): In a 2023 Nucleic Acids Research study (Leonaviciene & Mazutis), SPCs enabled in-capsule RT-PCR with fluorescent primers for digital detection of specific transcripts.
-
Protein detection: Atrandi’s white papers confirm theoretical compatibility with antibody-based staining, including DNA-barcoded antibodies, supporting workflows similar to CITE-seq.
-
Targeted genomic assays: SPCs can also be used for multiplexed genotyping via barcoded PCR, hybrid capture, and concatenated sequencing strategies.
-
Live-Cell Assays: In a Lab on a Chip 2020 study, bacterial clones were cultured and phenotyped inside SPCs before sequencing, demonstrating the ability to maintain viability and assay functionally.
-
Atrandi emphasizes SPCs as miniature bioreactors, capable of supporting high-throughput single-cell cultivation, observation (e.g. fluorescence or microscopy), and downstream analysis.
Software and Bioinformatics Support
Almost every vendor now offers its own in-house single-cell analysis platform to help customers realize the value of their kits more quickly.
That said, in many cases, it feels like each provider is re-inventing the wheel, primarily to gain the benefits of white-labeling and full control over how their analyses are presented. A great deal of bioinformatics talent ends up being spent on software engineering, UI development, and cloud hosting, tasks that should be easy to standardize but often become significant time sinks, pulling focus away from core computational biology or assay development work.
While platforms like BioTuring and ROSALIND exist, they are generic third-party tools. Using them often means sacrificing flexibility in algorithm design or visualization customization, both of which could be critical for showcasing the unique features of a vendor's kit.
There is room for innovation here, not just to build better visualization layers, but actual frameworks. Imagine developer-first products that provide clean APIs and tooling to deploy analysis pipelines quickly. This idea is not new in the tech sphere. Platforms like Vercel or Streamlit have done it well for abstracting a way the cloud hosting and UIs construction with simple APIs. Still, there is nothing purpose-built for large-scale single-cell analysis. Features like fast HDF5 operations, interactive annotation in a browser-based viewer, or lasso-selecting cells within a UMAP all remain fragmented across custom implementations.
A well-designed framework could dramatically reduce the time teams spend re-building infrastructure and let them focus instead on real science and (cool) impactful algorithms. (Note: this is a topic I spend a lot of time thinking about. If it resonates, reach out!)
Parting Thoughts
The landscape is getting crowded, but that's a good thing. It reflects a field moving fast, driven by real biological questions and the growing demand for resolution, scale, and functional depth. Each kit listed here represents a specific view on what matters most in single-cell biology: throughput, analyte diversity, multiomics, FFPE compatibility, software support, or live-cell function. No single platform will be best for every use case. We hope that through this article and the single-cell landscape database, researchers can more easily navigate the expanding ecosystem of technologies. Our goal is to help scientists find the right tools for their questions and to recognize the builders, often working quietly behind the scenes, who make those tools possible.