Alex (Qian) Wan: Alex (Qian) is a designer specializing in AI for B2B products. She is currently working at Microsoft, focusing on machine learning and Copilot for data analysis. Previously, she was the Gen AI design lead at VMware. Eli Ruoyong Hong: Eli is a design lead at Robert Bosch specializing in AI and immersive technology, developing systems that bridge technical innovation with human social dynamics to create more culturally aware and socially responsive technologies.
Background
Imagine you’re scrolling through social media and come across a post about a house makeover written in another language. Here’s a direct, word-for-word translation:
Finally, cleaned up this house completely and adjusted the design plan. Next, just waiting for the construction team to come in. Looking forward to the final result! Hope everything goes smoothly!
Illustration by Qian (Alex) Wan.
If you were the English translator, how would you translate this? Gen AI responded with:
I finally finished cleaning up this house and have adjusted the design plan. Now, I’m just waiting for the construction team to come in. I’m really looking forward to the final result and hope everything goes smoothly!
The translation seems to be clear and grammarly perfect. However, what if I told you this is a social post from a person who is notoriously known for exaggerating their wealth? They don’t own the house—they just left out the subject to make it seem like they do. Gen AI added “I” mistakenly without admitting the vagueness. A better translation would be:
The house has finally been cleaned up, and the design plan has been adjusted. Now, just waiting for the construction team to come in. Looking forward to seeing the final result—hope everything goes smoothly!
The languages where the “unstated” context plays an important role in literature and daily life are called “high-context language“.
Translating high-context languages such as Chinese and Japanese is uniquely challenging for many reasons. For instance, by omitting pronouns, and using metaphors that are highly associated with history or culture, translators are more dependent on context and are expected to have a deep knowledge of culture, history, and even differences among regions to ensure accuracy in translation.
This has been a long-time issue in traditional translation tools such as Google Translate and DeepL, but fortunately, we are in the era of Gen AI, the translation has significantly improved because of context-aware ability, and Gen AI is able to generate much more human-like content. Motivated by technological advancement, we decided to develop a Gen-AI powered translation browser extension for daily reading purpose.
Our extension uses Gen AI API. One of the challenges we encountered was choosing the AI model. Given the diverse options on the market, this has been a multi-month battle. We realized that there might be many people like us – not techy, with a lower budget, but interested in using Gen AI to bridge the language gap, so we tested 10 models with the hope of bringing insights to the audience.
This article documents our journey of testing different models for Chinese Japanese translation, evaluating the results based on specific criteria, and providing practical tips and tricks to resolve issues to increase translation quality.
Who might be interested in this article?
Anyone who is working or interested in using multi-language generative AI for topics like us: maybe you are a team member working for an AI-model tech company and looking for potential improvements. This article will help you understand the key factors that uniquely and significantly impact the accuracy of Chinese and Japanese translations.
It may also inspire you if you’re developing a Gen Ai Agent dedicated to language translation. If you happen to be someone who is looking for a high-quality Gen AI model for your daily reading translation, this article will guide you to select AI models based on your needs. You’ll also find tips and tricks to write better prompts that can significantly improve translation output quality.
Heads up
This article is primarily based on our own experience. We focused on certain Gen AI as of Feb 2, 2025 (when Gemini 2.0 and DeepSeek were released), so you might find some of our observations are different from current performance as AI models keep evolving.
We are non-experts, and we tried our best to show accurate info based on research and real testing. The work we did is purely for fun, self-learning and sharing, but we’re hoping to bring discussions to Gen AI’s cultural perspectives.
Many examples in this article are generated with the help of Gen AI to avoid copyright concerns.
Our initial Gen AI model selection
Our initial consideration was straightforward. Since our translation needs are related to Chinese, Japanese and English, the translation of the three languages was the priority. However, there were very few companies that detailed this ability specifically on their doc. The only thing we found is Gemini which specifies the performance of Multilingual.
Capability
Multilingual
Benchmark
Global MMLU (Lite)
Description
MMLU translated by human translators into 15 languages. The lite version includes 200 Culturally Sensitive and 200 Culturally Agnostic samples per language.
Second, but equally important, is the price. We were cautious about the budget and tried not to go bankrupt because of the usage-based pricing model. So Gemini 1.5 Flash became our primary choice at that time. Other reasons we decided to proceed with this model are that it’s the most beginner-friendly option because of the well-documented instructions and it has a user-friendly testing environment–Gemini AI studio, which causes even less friction when deploying and scaling our project.
Backup models
Now Gemini 1.5 Flash has set a strong foundation, during our first dry run, we found it has some limitations. To ensure a smooth translation and reading experience, we have evaluated a few other models as backups:
Grok-beta (xAI): In late 2024, Grok didn’t have as much fame as OpenA’s models, but what attracted us was zero content filters (This is one of the issues we observed from AI models during translation, which will be discussed later). Grok offered $20 free credits per month before 2025, which makes it an attractive, budget-friendly option for frugal users like us.
Deepseek-V3: We integrated Deeseek right after its stride into market because it has richer Chinese training data than other alternatives (They collaborated with staff from Peking University for data labeling). Another reason is its jaw-dropping low price: With the discount, it was nearly 1/100 of Grok-beta. However, the high response time was a big issue.
OpenAI GPT-4o: It has good documentation and strong performance, but we didn’t really consider this as an option because there is no free tier for low-budget constraints. We used it as a reference but did not actively use it. We will integrate it later just for testing purposes.
We also explored a hybrid solution – providers that offer multiple models:
Groq w/ Deepseek: it is first an integrated model platform to deploy Deepseek. This version is distilled from Meta’s LLM, although it’s 72B makes it less powerful but with acceptable latency. They offered a free tier but with noticeable TPM constraints
Siliconflow: A platform with many Chinese model choices, and they offered free credits.
Translation quality issues
When using those models for daily translation (mostly between languages Simplified Chinese, Japanese, and English). We found that there are many noticeable issues.
1. Inconsistent translation of proper nouns/terminology
When a word or phrase has no official translation (or has different official translations), AI models like to produce inconsistent replies in the same document.
For example, the Japanese name “Asuka” has multiple potential translations in Chinese. Human translators usually choose one based on character setting (in some cases, there is a Japanese kanji reference for it, and the translator could simply use the Chinese version). For example, a female character could be translated into “明日香”, and a male character might be translated as “飞鸟” (more meaning-based) or “阿斯卡” (more phonetical-based). However, AI output sometimes switches between different versions of the same text.
There are also many different official translations for the same noun in the Chinese-speaking regions. One example is the spell “Expecto Patronum” in Harry Potter. This has two accepted translations:
Although I specify prompts to the AI to translate to simplified Chinese, it sometimes goes back and forth between simplified and the traditional Chinese version.
2. Overuse of pronouns
One thing that Gen AI often struggles with when translating from lower context language to higher context language is adding additional pronouns.
In Chinese or Japanese literature, there are a few ways when referring to a person. Like many other languages, third-person pronouns like She/Her are commonly used. To avoid ambiguity or repetition, the 2 approaches below are also very common:
Use character names.
Descriptive phrases (“the girl”, “the teacher”).
This writing preference is the reason that the pronoun use is much less frequent in Japanese and Chinese. In Chinese literature. The pronoun during translation to Chinese is only about 20-30%, and in Japanese, this number could go lower.
What I also want to emphasize is this: There is nothing right or wrong with how frequently, when, and where to add the additional pronoun (In fact, it’s a common practice for translators), but it has risks because it can make the translated sentence unnatural and not align with reader’s reading habit, or worse, misinterpret the intended meaning and cause mistranslation.
Below is a Japanese-to-English translation:
Original Japanese sentence (pronoun omitted)
Jack sees the CEO entering the building. With confidence, excitement, and strong hope in heart, go to conference room.
AI-generated translation (w/ incorrect pronoun)
Jack sees the CEO entering the building. With confidence, excitement, and strong hope in his heart, he goes to the conference room.
In this case, the author intentionally avoids mentioning the pronoun, leaving room for interpretation. However, because the AI is trying to follow the grammar rules, it conflicts with the author’s design.
Better translation that preserves the original intent
Jack sees the CEO entering the building. With confidence, excitement, and strong hope in heart, heads to the conference room.
3. Incorrect pronoun usage in AI translation
The additional pronoun would potentially lead to a higher rate of incorrect pronouns caused by biased data; often, it’s gender-based errors. In the example above, the CEO is actually a woman, so this translation is incorrect. AI often defaults to male pronouns unless explicitly prompted
Jack sees the CEO entering the building. With confidence, excitement, and strong hope in his heart, heshe goes to the conference room.
Another common issue is AI overuses “I” in translations. For some reason, this issue persists across almost all models like GPT-4o, Gemini 1.5, Gemini 2.0, and Grok. GenAI models default to first-person pronouns when the subject is unclear.
4. Mix Kanji, Simplified Chinese, Traditional Chinese
Another issue we encountered was AI models mixing Simplified Chinese, Traditional Chinese, and Kanji in the output. Because of historical and linguistic reasons, many modern Kanji characters are visually similar to Chinese but have regional or semantic differences.
While some mix-use is incorrect but might be acceptable, for example:
Those three characters also look visually similar, and they share certain meanings, so it could be acceptable in some casual scenarios, but not for formal or professional communication.
However, other cases can lead to serious translation issues. Below is an example:
If AI directly uses this word when converting Japanese to Chinese (in a modern scenario), the sentence “Jane received a letter from her distant family” could end up with “Jane received a toilet paper from her distant family,” which is both incorrect and unintentionally funny.
Please note that the browser-rendered text can also have issues because of the lack of characters in the system font library.
5. Punctuation
Gen AI sometimes doesn’t do a great job of distinguishing punctuation differences between Chinese, Kanji and English. Below is one of the examples to show how different languages use distinct ways to write conversation (in modern common writing style):
This might seem minor but could impact professionalism.
6. False content filtering triggers
We also found that Gen AI content filter might be more sensitive to Japanese and Chinese (This happened when using Gemini 1.5 Flash). Even when the content was completely harmless. For example:
人並みにはできますよ!
I can do it at an average level!
Roughly speaking, there were about 2 out of 26 samples that triggered false content filters. This issue showed up randomly.
Evaluating Gen AI models
Completely out of curiosity and to better understand the Chinese/Japanese translation ability of different Gen AI models, we conducted structured testing on 10 models from 7 providers.
Testing setup
Task: Each AI model was used to translate an article written in Japanese into simplified Chinese through our translation extension. The Gen AI models were connected through API.
Sample: We selected a 30-paragraph third-person article. Each paragraph is a sample of which the character varies from 4 to 120.
Processed result: each model was tested three times, and we used the median result for analysis.
Evaluation metrics
We fully respect that the quality of translation is subjective, so we picked three metrics that are quantifiable and represent the challenges of high-context language translation.
Pronoun error rate
This metric represents the frequency of erroneous pronouns that appeared in the translated sample, which includes the following cases:
Gender pronoun incorrectness (e.g., using “he” instead of “she”).
Mistakenly switch from third-person pronoun to another perspective
A paragraph was marked as affected (+1) if any incorrect pronoun was detected.
Non-Chinese return rate
Some models randomly output Kanji, Hiragana, or Katakana in their responses. We were to count the samples that contained any of those, but every paragraph contained at least one non-Chinese character, so we adjusted our evaluation to make it more meaningful:
If the returned translation contains Hiragana, Katakana, or Kanji that affect readability, it will be counted as a translation error. For example: If the AI output 対 instead of 对, it won’t be flagged, since both are visually similar and do not affect meaning.
Our translation extension has a built-in non-Chinese characters function. If detected, the system retranslates the text up to three times. If the non-Chinese remains, it will display an error message.
Pronoun Addition Rate
If the translated sample contains any pronoun that doesn’t exist in the original paragraph, it will be flagged.
Scoring formula
All three metrics were calculated using the following formula. 𝑁 represents the number of affected paragraphs (samples). Please note, if a paragraph (sample) contains multiple same-type errors, it will be counted 1 time.
Rate=N/30*100%
Quality score: to have a better sense of overall quality. We also calculated the quality score by weighting the three metrics based on their impact on translation: Pronoun Error Rate > Non-CN Return Rate > Pronoun Addition Rate.
Model comparison 1: base
In the first run, we only provided a foundational prompt by specifying persona and translation tasks without adding any specific translation guidelines. The goal was to evaluate AI translation baseline performance.
Observation
Generally speaking, the overall translation quality is not sufficient enough to bring the audience an “optimal reading experience”.
For error return rate, even the highest-rated model, Claude 3.5 Sonnet, still got a 30% error rate. This means obvious translation deficiencies could be easily observed roughly 1 in every 4 sentences. Interestingly, we found that the incorrectly added pronouns were always first-person “I”. It might be because the distance between the word “I” is closer to the verb vectors than other pronouns in vector space.
Pronoun Addition Rates exceeded 50% in most models. This frequency is much more aligned with English writing habits than with Chinese (20–30%) or Japanese (even lower). This might stem from the AI model training data. According to OpenAI’s dataset statistics, GPT-3’s training data consists of 92.65% English, 0.11% Japanese, 0.1% Simplified Chinese, and 0.02% Traditional Chinese. The differences show training data focuses on English and revealed the potential reason for translating struggles, including the issue of mixing simplified Chinese and traditional Chinese in output, which was also observed in testing.
We did a few not-so-fancy solutions in order to have a consistent good translation.
Re-translation with different models
If conditions allow (budget and technical feasibility), you could use the backup models to re-translate cases that the primary model cannot translate. This applies to untranslated Japanese text (non-Chinese returns). We primarily used Grok-beta till mid-Jan 2025.
Translation guidance: pronoun
To prevent the AI from inserting subjects unnecessarily, we specifically instruct AI to ignore grammar rules. Here are the hints we use:
**Pronoun Handling Requirements:**
* **Pronoun Consistency** Follow the original text strictly.
* **Pronoun handling** Do not add subjects unless explicitly mentioned in the original text, even if it results in grammatical errors.
In the meantime, providing examples is pretty useful for AI to understand your requirements.
**Pronoun Handling**
* **Original Japanese sentence (subject omitted): ジャックは最高経営責任者が建物に入るのを見た。自信と興奮、そして強い希望を胸に、会議室へ向かった
* **Incorrect AI-generated translation (unnecessary subject added): Jack sees the CEO entering the building. With confidence, excitement, and strong hope in his heart, he goes to the conference room
* **Good example (grammatically correct without pronoun): Jack sees the CEO entering the building. With confidence, excitement, and strong hope in heart, heads to the conference room.
* **Acceptable example (omitted subject but grammatically incorrect): “Jack sees the CEO entering the building. With confidence, excitement, and strong hope in heart, go to conference room.”
Translation guidance: glossary
I also wrote a glossary list like below. This significantly reduces the appearance of erroneous pronouns and standardizes the terminology translation.
| Japanese | English | Chinese | Notes |
| シカゴ | Chicago | 芝加哥 | Official location name |
| 俺 | I | 我 | First-person pronoun, informal, bold, and rough in tone, mostly used by males | | アスカ | Asuka | 飞鸟 | A young male character name | …
Adjusting Model Parameters
Generally speaking, lowering the parameters helps avoid randomness. As someone who likes writing prompts, AI following the prompt more strictly is much more of a priority than being creative in output. So, we lowered top-p, top-k and temperature. Deepseek AI officially recommends a temperature of 1.3 for translation, but for better prompt adherence, we adjusted it to 1.0 or lower. TopK was reduced by 20. This works pretty well. Gemini 1.5 flash was used to randomly output a full paragraph content that didn’t exist in the original article. This issue never shows again after adjusting the parameters.
This method reduces variability but is not scalable, because each model responds differently depending on their size, advancement, etc.
Model comparison 2: With translation guidance
For the second round of the test, we apply the translation guidance as a comparison.
Observation
After applying translation guidance, the overall translation quality of all models improved significantly. Below is a detailed comparison of the performance of different AI models under these improved conditions.
You can easily tell that with translation guidance the translation quality has been significantly improved.
For the primary metric Pronoun Error Rate: Claude-3.5 Sonnet, OpenAI GPT-4o, DeepSeek V3, as the front runner, showed strong accuracy. Gemini 2.0 Flash and Moonshot-V1 (Kimi) had minor issues but were sufficient for most non-professional Japanese-to-Chinese translation needs.
Based on the result of the Pronoun Addition Rate. Claude-3.5 Sonnet strictly followed translation guidance and executed accurately with only an 8% Pronoun Addition Rate. Gemini 2.0 Flash had a 20% pronoun addition rate. It’s an acceptable result as it’s aligned with Chinese writing habits.
Choosing the right AI models for English-Chinese-Japanese translation
The best model selection depends on personal needs, considering factors such as budget, request per minute (RPM) limits, and ecosystem compatibility. Choosing an AI model for English-Chinese-Japanese translation.
For thosewithout budget constraints, Claude-3.5 Sonnet and OpenAI GPT-4o are the strongest choices because of their overall strong performance.
For entry-level developers in North America, Gemini 2.0 Flash is an excellent choice because of its affordable price, and good response time. Another reason we chose it as the primary provider is because Google’s cloud service ecosystem (OCR, cloud storage, etc.) makes it easier to scale development projects.
For Gen AI power users looking to balance price and quality, DeepSeek offers low prices, unlimited RPMs, and open-source flexibility. This is a strong choice for cost-sensitive users who don’t want to compromise translation quality. However, when using the official API platform in North America, we experienced long response time, which can be a limitation if you have a need for real-time or long-context translations. Fortunately, there are many services integrated DeepSeek on other servers (such as Microsoft Azure, Groq, and Siliconflow, or even you could deploy into your own local servers), or using it within China can avoid these issues. Additionally, model size can significantly affect translation performance – if you could, use the full-power 671B version for best results.
Limitations and considerations
We understand that those tests are not perfect. Even if we tried to ensure a diverse and right data volume, there is much room for improvement. For example, our sample size is not large enough for statistical significance. AI model performance fluctuates at any moment, issues like terminology translation inconsistency weren’t captured but might be important indicators for some audiences, and the translation quality wasn’t able to be reflected quantitatively. We provided the test just for learning and hopefully, serve as reference points for you.
Future of Gen AI translation
We are really grateful for the advances in Generative Ai, which have helped bridge the gap of language and make knowledge more accessible for people speaking different languages and from different cultures.
However, we can still see many challenges remain to be overcome—especially for non-English languages.
There is an opinion that translation doesn’t need advanced AI models, but“good enough” is not enough. I can see that this view might be correct from a cost perspective and makes sense from an English-centric perspective. However, if the standard “good” is based on official performance reports from AI providers, it might accurately reflect the performance of non-English translation. As you can clearly see, high-context languages such as Japanese and Chinese translation still struggle with accuracy and fluency. There is still a road ahead to improve AI translation quality, better contextual understanding and cultural awareness are necessary.
Cost
Deepseek has brought more competition to the AI translation market. Pricing is still a key factor for people and sometimes has more weight than performance.
If you have mid to high-volume daily translation needs (academic reading, news, video caption, etc.), using a premium model can cost anywhere from $20 to $80 per month. For businesses dealing with localization and internationalization, these costs would increase quickly.
No way around it: prompting for better translation
Another major challenge is AI models still require users to write long, complex prompts to achieve basic readability. For example, when translating professional topics in certain niche domains, I have no choice but to write prompts of over 5000 characters in English (almost writing an entire document) just to guide the AI to an acceptable quality. Not to mention the longer prompts = higher token usage.
If AI is truly going to break language barriers, there is still a lot of room for improvement to make translation models more accurate, more context-aware, and less dependent on long prompts. There’s still a lot of work to do to make AI translation easy, cost-effective, and truly accessible to everyone, but AI has already achieved more than anyone could have imagined, and I celebrate and am grateful for these technological advancements.
Medical practice administrators and IT managers in the United States often handle many patient interactions while making sure clinical documentation meets official
SACRAMENTO, Calif. — A judge has initiated a federal court takeover of California’s troubled prison mental health system by naming the former head of the Federal Bureau of Prisons to serve as receiver, giving her four months to craft a plan to provide adequate care for tens of thousands of prisoners with serious mental illness. Senior U.S. District Judge Kimberly Mueller issued her order March 19, identifying Colette Peters as the nominated receiver. Peters, who was Oregon’s first female corrections director and known as a reformer, ran the scandal-plagued federal prison system for 30 months until President Donald Trump took office in January. During her tenure, she closed a women’s prison in Dublin, east of Oakland, that had become known as the “rape club.” Michael Bien, who represents prisoners with mental illness in the long-running prison lawsuit, said Peters is a good choice. Bien said Peters’ time in Oregon and Washington, D.C., showed that she “kind of buys into the fact that there are things we can do better in the American system.” “We took strong objection to many things that happened under her tenure at the BOP, but I do think that this is a different job and she’s capable of doing it,” said Bien, whose firm also represents women who were housed at the shuttered federal women’s prison. California corrections officials called Peters “highly qualified” in a statement, while Gov. Gavin Newsom’s office did not immediately comment. Mueller gave the parties until March 28 to show cause why Peters should not be appointed. Peters is not talking to the media at this time, Bien said. The judge said Peters is to be paid $400,000 a year, prorated for the four-month period. About 34,000 people incarcerated in California prisons have been diagnosed with serious mental illnesses, representing more than a third of California’s prison population, who face harm because of the state’s noncompliance, Mueller said. Appointing a receiver is a rare step taken when federal judges feel they have exhausted other options. A receiver took control of Alabama’s correctional system in 1976, and they have otherwise been used to govern prisons and jails only about a dozen times, mostly to combat poor conditions caused by overcrowding. Attorneys representing inmates in Arizona have asked a judge to take over prison health care there. Mueller’s appointment of a receiver comes nearly 20 years after a different federal judge seized control of California’s prison medical system and installed a receiver, currently J. Clark Kelso, with broad powers to hire, fire, and spend the state’s money. California officials initially said in August that they would not oppose a receivership for the mental health program provided that the receiver was also Kelso, saying then that federal control “has successfully transformed medical care” in California prisons. But Kelso withdrew from consideration in September, as did two subsequent candidates. Kelso said he could not act “zealously and with fidelity as receiver in both cases.” Both cases have been running for so long that they are now overseen by a second generation of judges. The original federal judges, in a legal battle that reached the U.S. Supreme Court, more than a decade ago forced California to significantly reduce prison crowding in a bid to improve medical and mental health care for incarcerated people. State officials in court filings defended their improvements over the decades. Prisoners’ attorneys countered that treatment remains poor, as evidenced in part by the system’s record-high suicide rate, topping 31 suicides per 100,000 prisoners, nearly double that in federal prisons. “More than a quarter of the 30 class-members who died by suicide in 2023 received inadequate care because of understaffing,” prisoners’ attorneys wrote in January, citing the prison system’s own analysis. One prisoner did not receive mental health appointments for seven months “before he hanged himself with a bedsheet.” They argued that the November passage of a ballot measure increasing criminal penalties for some drug and theft crimes is likely to increase the prison population and worsen staffing shortages. California officials argued in January that Mueller isn’t legally justified in appointing a receiver because “progress has been slow at times but it has not stalled.” Mueller has countered that she had no choice but to appoint an outside professional to run the prisons’ mental health program, given officials’ intransigence even after she held top officials in contempt of court and levied fines topping $110 million in June. Those extreme actions, she said, only triggered more delays. The 9th U.S. Circuit Court of Appeals on March 19 upheld Mueller’s contempt ruling but said she didn’t sufficiently justify calculating the fines by doubling the state’s monthly salary savings from understaffing prisons. It upheld the fines to the extent that they reflect the state’s actual salary savings but sent the case back to Mueller to justify any higher penalty. Mueller had been set to begin additional civil contempt proceedings against state officials for their failure to meet two other court requirements: adequately staffing the prison system’s psychiatric inpatient program and improving suicide prevention measures. Those could bring additional fines topping tens of millions of dollars. But she said her initial contempt order has not had the intended effect of compelling compliance. Mueller wrote as far back as July that additional contempt rulings would also be likely to be ineffective as state officials continued to appeal and seek delays, leading “to even more unending litigation, litigation, litigation.” She went on to foreshadow her latest order naming a receiver in a preliminary order: “There is one step the court has taken great pains to avoid. But at this point,” Mueller wrote, “the court concludes the only way to achieve full compliance in this action is for the court to appoint its own receiver.” This article was produced by KFF Health News, which publishes California Healthline, an editorially independent service of the California Health Care Foundation. If you or someone you know may be experiencing a mental health crisis, contact the 988 Suicide & Crisis Lifeline by dialing or
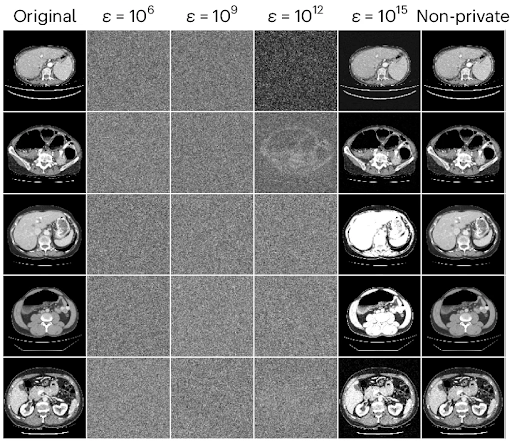
Imagine you’re building your dream home. Just about everything is ready. All that’s left to do is pick out a front door. Since the neighborhood has a low crime rate, you decide you want a door with a standard lock — nothing too fancy, but probably enough to deter 99.9% of would-be burglars. Unfortunately, the local homeowners’ association (HOA) has a rule stating that all front doors in the neighborhood must be bank vault doors. Their reasoning? Bank vault doors are the only doors that have been mathematically proven to be absolutely secure. As far as they’re concerned, any front door below that standard may as well not be there at all. You’re left with three options, none of which seems particularly appealing: Concede defeat and have a bank vault door installed. Not only is this expensive and cumbersome, but you’ll be left with a front door that bogs you down every single time you want to open or close it. At least burglars won’t be a problem! Leave your house doorless. The HOA rule imposes requirements on any front door in the neighborhood, but it doesn’t technically forbid you from not installing a door at all. That would save you a lot of time and money. The downside, of course, is that it would allow anyone to come and go as they please. On top of that, the HOA could always close the loophole, taking you back to square one. Opt out entirely. Faced with such a stark dilemma (all-in on either security or practicality), you choose not to play the game at all, selling your nearly-complete house and looking for someplace else to live. This scenario is obviously completely unrealistic. In real life, everybody strives to strike an appropriate balance between security and practicality. This balance is informed by everyone’s own circumstances and risk analysis, but it universally lands somewhere between the two extremes of bank vault door and no door at all. But what if instead of your dream home, you imagined a medical AI model that has the power to help doctors improve patient outcomes? Highly-sensitive training data points from patients are your valuables. The privacy protection measures you take are the front door you choose to install. Healthcare providers and the scientific community are the HOA. Suddenly, the scenario is much closer to reality. In this article, we’ll explore why that is. After understanding the problem, we’ll consider a simple but empirically effective solution proposed in the paper Reconciling privacy and accuracy in AI for medical imaging [1]. The authors propose a balanced alternative to the three bad choices laid out above, much like the real-life approach of a typical front door. The State of Patient Privacy in Medical AI Over the past few years, artificial intelligence has become an ever more ubiquitous part of our day-to-day lives, proving its utility across a wide range of domains. The rising use of AI models has, however, raised questions and concerns about protecting the privacy of the data used to train them. You may remember the well-known case of ChatGPT, just months after its initial release, exposing proprietary code from Samsung [2]. Some of the privacy risks associated with AI models are obvious. For example, if the training data used for a model isn’t stored securely enough, bad actors could find ways to access it directly. Others are more insidious, such as the risk of reconstruction. As the name implies, in a reconstruction attack, a bad actor attempts to reconstruct a model’s training data without needing to gain direct access to the dataset. Medical records are one of the most sensitive kinds of personal information there are. Although specific regulation varies by jurisdiction, patient data is generally subject to stringent safeguards, with hefty fines for inadequate protection. Beyond the letter of the law, unintentionally exposing such data could irreparably damage our ability to use specialized AI to empower medical professionals. As Ziller, Mueller, Stieger, et al. point out [1], fully taking advantage of medical AI requires rich datasets comprising information from actual patients. This information must be obtained with the full consent of the patient. Ethically acquiring medical data for research was challenging enough as it was before the unique challenges posed by AI came into play. But if proprietary code being exposed caused Samsung to ban the use of ChatGPT [2], what would happen if attackers managed to reconstruct MRI scans and identify the patients they belonged to? Even isolated instances of negligent protection against data reconstruction could end up being a monumental setback for medical AI as a whole. Tying this back into our front door metaphor, the HOA statute calling for bank vault doors starts to make a little bit more sense. When the cost of a single break-in could be so catastrophic for the entire neighborhood, it’s only natural to want to go to any lengths to prevent them. Differential Privacy (DP) as a Theoretical Bank Vault Door Before we discuss what an appropriate balance between privacy and practicality might look like in the context of medical AI, we have to turn our attention to the inherent tradeoff between protecting an AI model’s training data and optimizing for quality of performance. This will set the stage for us to develop a basic understanding of Differential Privacy (DP), the theoretical gold standard of privacy protection. Although academic interest in training data privacy has increased significantly over the past four years, principles on which much of the conversation is based were pointed out by researchers well before the recent LLM boom, and even before OpenAI was founded in 2015. Though it doesn’t deal with reconstruction per se, the 2013 paper Hacking smart machines with smarter ones [3] demonstrates a generalizable attack methodology capable of accurately inferring statistical properties of machine learning classifiers, noting: “Although ML algorithms are known and publicly released, training sets may not be reasonably ascertainable and, indeed, may be guarded as trade secrets. While much research has been performed about the privacy of
SQA Regulatory Surveillance Summary for March and April 2023 By: Laurel Hacche, Rocio Cabeza, and Debra Cortner Agência Nacional de Vigilância Sanitária (ANVISA) ANVSA Recommends Intensification of Actions Against Arboviruses, 22 March 2023 ANVISA has published Technical Note 12/2023 which recommends the intensification of measures or the reduction of mosquito breeding sites and control of adult vectors, airports, and border areas, which are points of entry and exit of the country. The objective is to reinforce actions for the prevention and control of diseases such as dengue and chikungunya, arboviruses transmitted by the Aedes aegypti mosquito. As recommended by the International Health Regulations (IHR), there must be a vector-free zone at seaports, airports, and land crossing and within a perimeter of 400 meters around these entry points. For this, it is necessary to maintain regular active surveillance and vector control so that the risk of disease transmission is reduced. ANVISA Resumes Inspections in the Area of Technovigilance, 29 March 2023 In partnership with local Health Surveillance, ANVISA technical teams carried out in March 2023 two (2) medical device manufacturer inspections with an aim to strengthen the monitoring of these products in Brazil, ensuring their safety, performance, and quality. The technovigilance inspection consists of: Evaluation of compliance with technovigilance standards by companies Monitor the behavior of products in the post-marketing phase Evaluate the effectiveness of filed actions that affect medical devices Collect data and information of adverse events and technical complaints, as well as evaluate the investigative process triggered by the registration holder in the face of such situations The selection of companies for inspection includes the following criteria: silent companies (absence of notifications of adverse events, technical complaints, or field actions), quantity of products regulated by ANVISA and the risk class of these products. ANVISA Warns of New Cases of Botulinum Toxin Counterfeiting, 05 April 2023 ANVISA alerts health professionals and the population to the fact that new cases of adulteration/falsification of the drug Botox® 100U (botulinum toxin A), Batch Number C6835C3 have been identified. ANVISA has intercepted international shipments of Batch Number C6835C3 which presented a false description of content and contained bottles in packaging in the Turkish language with expirations dates 10/2024 (bottle) and 12/2024 (secondary packaging). The company that holds the registration of the drug Botox, Allergan Produtos Farmacêuticos Ltda., confirmed to ANVISA that the original Batch Number C6835C3 has a shelf life of 12/2023 and was marketed only in Turkey, and has not been imported into Brazil by official means. Thus the seizer and prohibition of marketing, distribution, and use of Batch Number C6835C3 was determined by means of Resolution-RE 796 of March 9, 2023. China: National Medical Products Administration (NMPA) China Update: Announcement No. 124 of 2022; Draft Guidelines for the Registration of Implantable Medical Devices, 06 January 2023 The NMPA and Center for Medical Device Evaluation (CMDE) published new rules for the supervision and management of enterprises implementing medical device safety, as well as draft guidelines for the registration and review of implantable medical device batteries. Following the draft consultation in November 2022, the NMPA announced the issuance of the Regulations on the Supervision and Management of Enterprises Implementing the Main Responsibility for the Quality and Safety of Medical Devices, which will come into force on 01 March 2023. This requires medical device registrants and record filers to fulfill the main responsibility for medical device quality and safety. It also includes provisions that emphasize the implementation of responsibilities for medical device registrants, filers, and entrusted manufacturers and personnel in key positions of quality and safety in medical device production and operating enterprises. The Interpretation of Regulations on the Supervision and Management of Enterprises Implementing the Main Responsibility for the Quality and Safety of Medical Devices further discusses the provisions of the Regulations. 2022 Recap & 2023 Outlook: China Pharmaceutical Regulatory Updates, 28 February 2023 In 2022, China issued and implemented a series of drug regulations, including new rules for marketing authorization holders to manage drug quality and guidelines for pharmacovigilance inspections. Last year also saw China’s first regulation permitting online sales of prescription drugs nationwide. The regulations impact how pharmaceutical companies apply for marketing authorization, sell drug products, ensure drug safety, and fulfill other obligations. ChemLinked BaiPharm Team held this webinar to review the significant regulatory updates, which can help stakeholders keep compliant with current regulations and prepare for the upcoming ones. Key points for the webinar include: China’s Drug Regulatory System 2022 Regulatory Updates 2023 Outlook European Commission (EC) New European MDCG Guidance on Medical Device Vigilance Requirements, 17 February 2023 The long-awaited Medical Device Coordination Group (MDCG) Guidance on Vigilance has been published to the European Commission website. MDCG 2023-3, Questions and Answers on Vigilance Terms and Concepts as Outlined in the Regulation (EU) 2017/745 on Medical Devices, provides additional information on key vigilance terms. Interestingly, the guidance only covers devices under the scope of the Medical Devices Regulation (MDR) and not those under the scope of the In Vitro Diagnostic Medical Devices Regulation (IVDR). The guidance clarifies key differences in vigilance reporting between MEDDEV 2.12/1 rev.8 and the Regulations: The guidance features a flowchart that illustrates the process of analyzing complaints to determine reportability under the MDR. The difference between the term “incident” and the new term “serious incident” introduced in the Regulation are also discussed in detail. The deadline for reporting serious incidents not constituting serious public health threats, deaths, or unanticipated serious deteriorations in state of health was reduced to 15 calendar days. The reporting period begins on the day after the awareness date of a serious incident. The awareness date may change if, during the investigation of an incident, the manufacturer receives additional information which subsequently changes the determination of the report to a serious incident. Although the original awareness date in Section 1.2c of the Manufacturer Incident Report (MIR) should still be identified, an explanatory comment may be placed within Section 5 of the MIR. It can be challenging to understand when the MIR report type, Final (non-reportable), may be used.
Exercise-induced bronchoconstriction (EIB), previously EIA, results in airway constriction during or following exercise, and wheezing, coughing, and breathlessness. Cold, dry air, allergens, pollution, and vigorous exercise are typical precipitants; swimming is frequently less of a problem because warm, humid air is breathed. Warming up, the use of a rescue inhaler, the selection of appropriate activities, nasal breathing, and air quality monitoring are all management options. Ever felt like you are gasping for air after a workout, even when you are in good shape? If your breathing gets tight, wheezy, or downright difficult during or after exercise, you might have exercise-induced asthma (EIA), now called exercise-induced bronchoconstriction (EIB). But do not worry, it does not mean you have to give up your favorite activities. With the right game plan, you can keep moving without gasping for air! What Exactly is Exercise-Induced Asthma EIA happens when physical activity causes your airways to narrow, making it harder to breathe. Symptoms like wheezing, coughing, and shortness of breath usually kick in a few minutes into exercise, peak shortly after stopping, and can last up to an hour. It is more common in cold, dry air or when you are exposed to triggers like pollen, pollution, or strong smells. Unlike regular breathlessness from being out of shape, EIA comes with a tight, wheezy chest feeling that just would not go away easily. The culprit? Fast breathing through the mouth. Normally, your nose warms and humidifies the air before it reaches your lungs, but when you breathe hard through your mouth, especially in cold weather, you skip that built-in filter, and your airways react by tightening up. What Triggers Exercise-Induced Asthma EIA can be triggered by: Cold, arid air, typical of winter sports such as skiing or racing in cold climates. Allergens such as pollen, pet dander, or dust may exacerbate symptoms. Smog & pungent smells of automobile exhaust, smoke, or perfumes can irritate respiratory passages. Interestingly, swimming is usually easier on the lungs because of the warm, humid air around pools, while activities like running or cycling in cold air tend to be tougher. Controlling and Staving Off Symptoms The best part? EIA is completely controllable with a few intelligent tactics: Gradually warm up first and begin slowly with stretching or a gentle jog to help your lungs get underway. Inhaling a rescue inhaler along with medications such as Albuterol prevents symptoms if done prior to exercise. Selecting the appropriate exercises such as swimming, walking, and yoga are excellent choices less likely to trigger EIA. Breathe in through your nose that serves to warm and filter the air before it reaches your lungs. Monitor the air quality for pollution or pollen levels, if it is high, opt for indoor exercises. Staying Active with EIA Just because you have EIA does not mean you have to sit on the sidelines. Opt for sports with short bursts of activity (like baseball or golf) instead of endurance-heavy exercises. If running is your thing, try intervals with walking breaks. And if cold air is a problem, covering your mouth with a scarf or mask will trap in moisture and warmth. Most of all, see your doctor if the symptoms persist. He may suggest a change in medication or some breathing exercises to keep your lungs at peak performance. By doing it the right way, you can stay active, stay healthy, and breathe easy—no matter your exercise of preference!
Hey! Experiencing shortness of breath, wheezing, or persistent coughing? Wondering if it is just allergies or something more serious? Asthma affects millions, yet many people struggle to identify its triggers and symptoms. Understanding them can help you manage the condition effectively and improve your quality of life. Asthma is a chronic respiratory condition that various factors can trigger, yet misconceptions often prevent proper management. Recognizing common triggers and symptoms is essential for better control and treatment. Myth 1: Asthma Only Affects Children. Fact: Asthma can develop at any age. While it is common in children, many adults are diagnosed later in life. Myth 2: You Can Outgrow Asthma. Fact: While some children see an improvement in symptoms as they grow older, asthma is a lifelong condition that may return or worsen over time. Myth 3: People With Asthma Should Avoid Exercise. Fact: While exercise can sometimes trigger symptoms, regular physical activity can actually strengthen the lungs. Proper management and medications can help individuals with asthma stay active. Myth 4: Asthma Attacks Only Happen Due to Allergens. Fact: While allergens like pollen and dust can be triggers, asthma attacks can also be caused by cold air, stress, respiratory infections, and even strong odors. Myth 5: Inhalers Are Addictive. Fact: Inhalers are a safe and essential part of asthma management. They are not addictive, but they must be used correctly as prescribed by a doctor. Myth 6: If You Are Not Wheezing, You Do Not Have Asthma. Fact: Not all asthma patients experience wheezing. Symptoms can include coughing, chest tightness, and difficulty breathing, which may be mistaken for other conditions. Understanding asthma and separating myths from facts can help individuals manage symptoms effectively and reduce the risk of severe attacks. Don’t let myths cloud your understanding—know the facts, control your asthma, and breathe easier! By spreading awareness, we can support those living with asthma and encourage better respiratory health.
Send Us Email
Livechat
FAQ
X
"Hello! Let’s get started on your journey with us."
Site SearchBusiness ServicesBusiness Services
×
Meet Eve: Your AI Training Assistant
Welcome to Enlightening Methodology! We are excited to introduce Eve, our innovative AI-powered assistant designed specifically for our organization. Eve represents a glimpse into the future of artificial intelligence, continuously learning and growing to enhance the user experience across both healthcare and business sectors.
In Healthcare
In the healthcare category, Eve serves as a valuable resource for our clients. She is capable of answering questions about our business and providing "Day in the Life" training scenario examples that illustrate real-world applications of the training methodologies we employ. Eve offers insights into our unique compliance tool, detailing its capabilities and how it enhances operational efficiency while ensuring adherence to all regulatory statues and full HIPAA compliance.
Furthermore, Eve can provide clients with compelling reasons why Enlightening Methodology should be their company of choice for Electronic Health Record (EHR) implementations and AI support. While Eve is purposefully designed for our in-house needs and is just a small example of what AI can offer, her continuous growth highlights the vast potential of AI in transforming healthcare practices.
In Business
In the business section, Eve showcases our extensive offerings, including our cutting-edge compliance tool. She provides examples of its functionality, helping organizations understand how it can streamline compliance processes and improve overall efficiency.
Eve also explores our cybersecurity solutions powered by AI, demonstrating how these technologies can protect organizations from potential threats while ensuring data integrity and security.
While Eve is tailored for internal purposes, she represents only a fraction of the incredible capabilities that AI can provide. With Eve, you gain access to an intelligent assistant that enhances training, compliance, and operational capabilities, making the journey towards AI implementation more accessible.
At Enlightening Methodology, we are committed to innovation and continuous improvement. Join us on this exciting journey as we leverage Eve's abilities to drive progress in both healthcare and business, paving the way for a smarter and more efficient future.
With Eve by your side, you're not just engaging with AI; you're witnessing the growth potential of technology that is reshaping training, compliance and our world! Welcome to Enlightening Methodology, where innovation meets opportunity!